

AI Coding Break-Even: Cheap Tokens, Expensive Software
Why the real crossover in enterprise software is review, repair, and delivery overhead, not token price.

I keep seeing the same chart in AI budget discussions. Token bill on one side, developer salary on the other, tiny AI bar, giant human bar, conclusion achieved.
I do not like that chart because it prices the easiest part of software and quietly ignores the rest.
Enterprise teams do not buy keystrokes. They buy a change that made it through product scoping, design, implementation, review, testing, security checks, release plumbing, and production. If you compare tokens to one developer writing code, you are comparing a narrow input cost to a full delivery salary and acting surprised when the machine looks cheap.
As of May 21, 2026, OpenAI lists GPT-5.4 at $2.50 per million input tokens and $15 per million output tokens. Anthropic lists Claude Sonnet 4 at $3 per million input tokens and $15 per million output tokens. Those are real numbers, and they are low enough that I am not going to pretend otherwise. AI-assisted coding is cheap on raw tokens.
The problem is that raw tokens are rarely where enterprise software wins or loses money.
The AI side is a spend band, not a number
The first thing I would stop doing is talking about “the AI cost” as if it were one number.
Anthropic’s Claude Code cost guide says the average across enterprise deployments is around $13 per developer per active day, roughly $150 to $250 per developer per month, and still below $30 per active day for 90% of users. That is a useful center of gravity. It tells you what ordinary enterprise usage looks like when people are not trying to become folklore on Hacker News.
The public ceiling is a different story. I pulled the live HN Tokenmaxxing feed on May 21, 2026 and recomputed the trailing seven-day window. That sample showed 28 active users, about $54,739.46 in total spend, a median active-user cost of $98.25 per day, an average of $279.28 per day, and top users burning $4,575 to $9,381 per week each.
Those numbers are not contradictory. They describe different populations.
Anthropic gives you a managed enterprise baseline. Tokenmaxxing gives you a public power-user ceiling full of people who use long context, multiple agents, and enough model calls to make finance curious. It is useful precisely because it is a bit unhinged. It shows the upper edge of behavior once teams stop treating AI like autocomplete and start treating it like a second operating mode.
It also moves around. Ten days earlier, the same public sample produced a materially higher median. That is another reason I would not build a strategy deck around one leaderboard screenshot. The AI side of the curve is a spend band, not a point estimate.
The denominator is the whole delivery chain
The usual chart also cheats on the human side.
To make the comparison less fuzzy, I modeled one modest enterprise feature slice using BLS median wages for the roles that usually touch real delivery work, then converted those wages to loaded employer cost using the BLS private-industry compensation release published March 20, 2026. That multiplier comes out to about 1.43x wages.
The feature slice is intentionally ordinary: six hours of product or project work, six hours of design, 24 hours of implementation, eight hours of QA, three hours of security review, three hours of release or ops work, and four hours of management or review coordination. Nothing heroic. Nothing transformation-program sized. Just a change that still has to survive the whole system.
That model lands at about $4,496 in loaded labor cost.
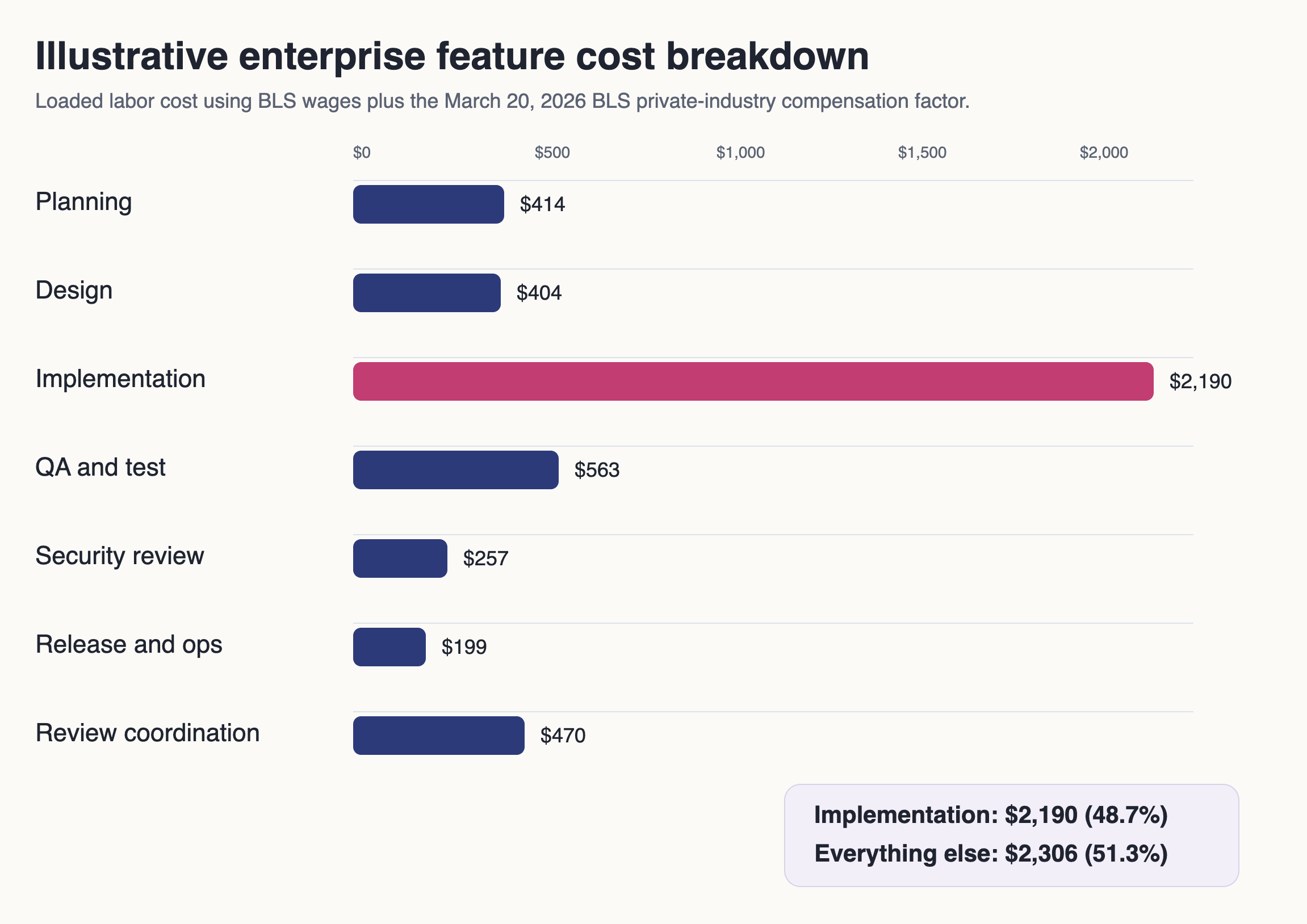
Implementation is only 48.7% of the bill. Planning, design, QA, security, release, and coordination are the other 51.3%.
That is the part the token-versus-salary chart keeps deleting. Even if code generation gets dramatically cheaper, more than half the lifecycle bill is still waiting for you after the model says it is done. Software is full of second-order costs. The model only touches some of them.
Break-even is a review curve
If I had to keep one chart and throw away the rest, I would keep the review curve.
The useful x-axis is not tokens. It is human review and repair hours required after the AI run.
For the same coding-shaped unit of work, the comparison is simple:
Human-only cost = loaded developer time
AI-led cost = model spend + human review and repair time
Using the feature model above, a loaded developer day is about $730, or about $91.25 per hour. Once you combine that with the current spend bands from Anthropic and Tokenmaxxing, you get this:
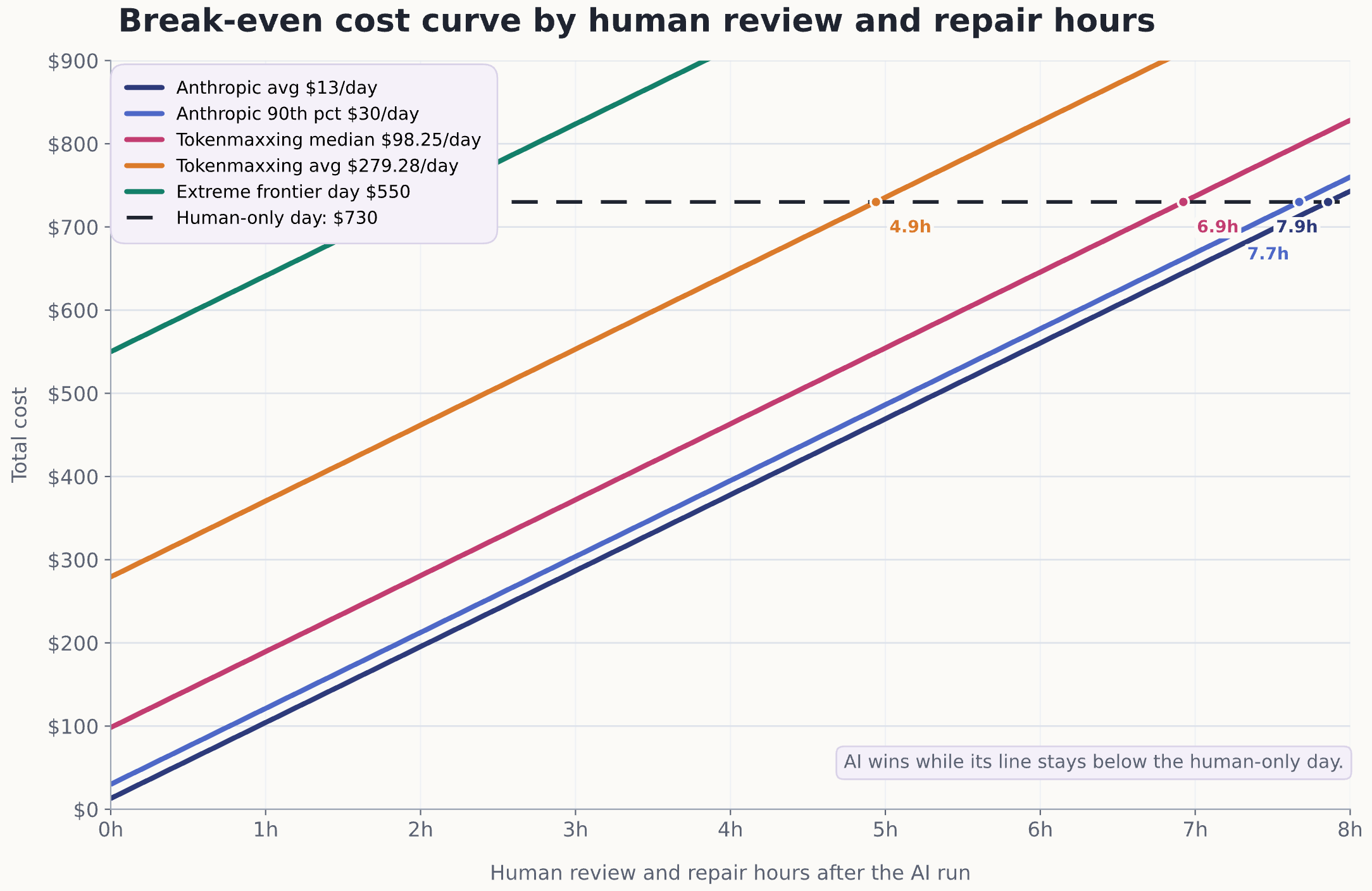
At Anthropic’s enterprise average of $13 per active day, AI still beats a human day on raw cost until the human spends almost 7.9 hours reviewing and repairing it. At Anthropic’s 90th-percentile ceiling of $30 per active day, the crossover is still about 7.7 hours. At the current Tokenmaxxing median of $98.25 per day, the crossover drops to about 6.9 hours. At the current Tokenmaxxing average of $279.28 per day, the crossover drops to about 4.9 hours. At an intentionally ugly frontier day of $550, you only get about 2.0 hours of human cleanup before AI loses the raw coding-day comparison.
That is the real question for engineering leaders:
How many hours of senior-human verification, correction, and coordination does this class of task usually need after the model claims success?
Once you ask it that way, the task sorting gets a lot less mystical.
Where AI is actually strong
I think there are three broad zones.
AI-led work is the place where the output is cheap to check and the blast radius is tightly bounded. Repo search, code explanation, narrow transforms, test scaffolding with a known oracle, documentation drafts, log triage, and boring CRUD inside one known framework all live here. These are the tasks where the Anthropic-style $13 to $30 active day economics are genuinely compelling because the review burden stays low.
Hybrid work is where most serious teams will make their money. Bounded feature work inside one service, behavior-preserving refactors, migration scripts with rollback paths, build repairs with a fast verification loop, and bug fixes anchored by deterministic tests fit here. AI can do a lot of the drafting and search. A human still has to own the change shape, the acceptance criteria, and the final judgment. In this zone, pure human work wastes cheap drafting power and fully agentic work creates expensive recovery loops.
Human-led work returns the moment review, coordination, or ambiguity starts dominating the bill. Product discovery, architecture under uncertainty, security and compliance changes, cross-team design, rollout strategy, incident response, and distributed-systems behavior under failure all live here. The model may still help, often a lot, but it is helping around the edges of the expensive thing. It is not replacing the expensive thing.
That is why I do not find “AI replaces a developer” especially useful as a framing for enterprise software. At best, AI replaces or compresses some implementation-shaped slices inside a much larger chain of work.
The rest of the evidence points the same way
Google’s 2024 DORA report summary is one of the more interesting reports because it refuses to tell a neat success story. More AI adoption was associated with better documentation quality, better code quality, and faster code review. It was also associated with lower delivery throughput and lower delivery stability. DORA’s later write-up on balancing AI tensions in the SDLC says the quiet part out loud: teams often spend the saved drafting time on auditing and verification.
That fits the curve almost perfectly. AI speeds up local creation. The bill comes back during checking.
METR’s July 2025 study found that experienced open-source developers working in large repositories they already knew well took 19% longer when AI tools were allowed. The 2026 follow-up says current uplift is harder to measure cleanly because tools improved, people increasingly refuse to work without them, and high-leverage usage patterns keep changing. That is a very modern research result. The tools matter. The measurement is messy. Anyone selling you one permanent productivity number is enjoying the simplicity more than the truth.
Security tells the same story from a less cheerful angle. GitGuardian’s 2026 State of Secrets Sprawl report says public GitHub saw about 29 million newly leaked hardcoded secrets in 2025, and that AI-assisted commits leak secrets at roughly 2x the baseline rate. Cheap generation is still cheap when it creates a secret leak. The expensive part arrives later, with rotation, cleanup, review, and the very ordinary question of who signed off on the thing.
Even the MIT numbers people like to quote need more care than they usually get. Project Iceberg’s report says 11.7% of U.S. wage value is technically exposed to current AI capability. That is interesting. It is also a statement about technical exposure, not a clean proof of near-term economic replacement in enterprise software organizations with real delivery, security, and coordination costs.
The takeaway I would give an engineering leader
If you run an engineering team, platform group, or budget process, my takeaway is pretty simple.
Do not ask whether AI is cheaper than developers. Ask whether AI lowers the total cost of getting a production-worthy change through your delivery system once review, repair, security, rollout, and coordination are included.
That changes what you measure.
Track review and repair hours alongside model spend
Track rework after review, not just output volume
Track escaped defects, hotfixes, and rollback rate
Track security findings and secret exposure
Track cycle time to a trusted production change, not just time to first draft
If those numbers improve, I do not care if the token bill goes up. You bought leverage.
If output volume goes up while review pain, rework, and incidents stay flat or get worse, you probably bought a faster typing machine and a more expensive queue behind it.
Cheap tokens matter. Expensive software still matters more. The real break-even point is where human review, repair, and lifecycle coordination start growing faster than the AI draft got cheaper.