

Can You Really Detect AI Writing? Let’s Build a Detector in Java with Quarkus and LangChain4j
A hands-on exploration of how far text analysis, OpenNLP, and embeddings can go in separating human from AI-generated writing and what that means for developers.


Someone recently accused me of writing with AI.
Not in a malicious way: More like a half-joking “Come on, Markus, no human writes that many posts.”
It wasn’t the first time. I’ve said before, in “Does Mastery Still Matter?”, that I use AI as a creative partner, not a ghostwriter. Still, the comment made me pause. What would an actual detector say about my writing? Could it tell which pieces were written by me and which were AI-assisted?
That curiosity turned into this tutorial.
Why Human vs. AI Text Identification Is So Hard
Before writing any code, it’s worth acknowledging something uncomfortable:
detecting whether a piece of text was written by a human or an AI model is almost impossible to do reliably.
Style Convergence
Early language models wrote like interns trying too hard: tidy sentences, repetitive transitions, no voice. But modern models like GPT-4, Claude, Gemini, and Mistral have learned to mimic real people. Their outputs vary by tone, humor, and even cultural nuance.
As a result, statistical differences between human and machine text are collapsing.
In other words: as models get smarter, old detectors get blind.
False Positives and Bias
Perplexity, or the measure of how “predictable” a sequence of words is, underpins many detection systems.
AI-generated text tends to be highly predictable. But so does writing from non-native English speakers, students, or professionals using formal style guides.
This creates structural bias.
In 2023, OpenAI quietly retired its AI Text Classifier because of “low accuracy, especially on short inputs.”
The takeaway: statistical methods are not just inaccurate, they can be unfair.
Model Drift and Temporal Decay
Even if you train a strong detector today, it’ll be obsolete in months.
Each new model generation rewrites the playbook. With changing syntax, sentence rhythm, and vocabulary distribution.
This “temporal decay” effect was detailed in DetectGPT (Mitchell et al., 2023), which found detection accuracy dropped by up to 35% within six months as model outputs evolved. Unless continuously retrained, detection models decay just like antivirus definitions.
The Paradox of Creativity
Ironically, the better a human writer becomes, the more their work looks like AI.
Perfect grammar, consistent tone, balanced arguments. All these are signs of good writing and unfortunately also marks of machine text. Meanwhile, LLMs are increasingly trained to inject imperfection and emotional variance.
This is the AI detection paradox:
Human mastery and machine fluency are converging toward the same aesthetic.
It’s why I often tell people: if your writing is clean, structured, and consistent, an algorithm will probably call it “AI.”
Semantic Overlap and Training Leakage
Another hidden trap is semantic overlap.
Most AI models are trained on internet-scale data, including public blogs, essays, and documentation. If your writing resembles what the model was trained on, embedding-based detectors may falsely flag it as AI because of vector-space proximity, not authorship.
Your unique post might simply be “too familiar” to the model.
Human Error and Subjectivity
Humans are no better.
A Nature Human Behaviour study in 2022 showed that even experienced editors and professors couldn’t distinguish GPT-4 essays from student essays better than random chance (Jakesch et al., Human heuristics for AI-generated language are flawed, 2022).
When people guess, they often rely on vibes. Similar to how polished, balanced, or “too coherent” something feels. But that says more about human expectation than authorship.
What We Can Detect, and What We Can’t
So what’s left?
Only probabilistic signals:
Predictability and uniformity (low burstiness)
Limited lexical diversity
Overuse of formulaic transitions (“overall”, “in conclusion”)
Even sentence rhythm and symmetry
Semantic closeness to known AI text
They don’t prove anything. They just provide evidence. Little more than hints that a piece of text might lean toward machine generation.
Our goal in this tutorial is to build a transparent detector, not a judge.
It won’t “catch” AI. It will show its reasoning, reveal uncertainty, and help you understand why some writing feels human and some doesn’t.
That, to me, is a far more honest form of detection.
Foundation Setup
1.1 Prerequisites
Java 17
Maven 3.9+
Quarkus 3.28.x (or 3.27 LTS)
Ollama installed locally with
mxbai-embed-large:335m(link)The Sentence Detector model for OpenNLP (en-sent.bin) (link)
And, as usual, you are more than welcome to clone, fork, download the complete project from my Github repository.
1.2 Project Bootstrap
quarkus create app com.example:ai-detector \
-x rest-jackson,rest-qute,langchain4j-ollama
cd ai-detectorAdd dependencies in pom.xml:
<dependencies>
<!-- Apache OpenNLP for linguistic analysis -->
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-tools</artifactId>
<version>2.5.6.1</version>
</dependency>
<!-- Commons Math for burstiness/variance -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.6.1</version>
</dependency>REST API and Input Handling
We’ll start with a simple REST API that accepts a text sample, runs analysis, and returns results as JSON. Delete the GreetingResource and SomePage.java before you continue to create:
src/main/java/com/example/api/DetectionResource.java:
package com.example.api;
import com.example.service.AnalysisService;
import jakarta.inject.Inject;
import jakarta.ws.rs.*;
import jakarta.ws.rs.core.MediaType;
import java.util.Map;
@Path(”/api/detect”)
@Consumes(MediaType.APPLICATION_JSON)
@Produces(MediaType.APPLICATION_JSON)
public class DetectionResource {
@Inject
AnalysisService service;
@POST
public Map<String, Object> detect(Map<String, String> body) {
String text = body.getOrDefault(”text”, “”);
return service.analyze(text);
}
}Statistical Detection Features
Statistical signals often distinguish human writing from machine text—up to a point. AI tends to be more consistent, humans more chaotic.
We’ll measure this chaos with a few metrics.
Text Processing with OpenNLP
First, initialize OpenNLP components.
src/main/java/com/example/nlp/TextAnalyzer.java:
package com.example.nlp;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashSet;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import org.apache.commons.math3.stat.descriptive.DescriptiveStatistics;
import jakarta.enterprise.context.ApplicationScoped;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.tokenize.SimpleTokenizer;
@ApplicationScoped
public class TextAnalyzer {
private final SentenceDetectorME sentenceDetector;
private final SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;
public TextAnalyzer() {
try (InputStream modelIn = getClass().getResourceAsStream(”/models/en-sent.bin”)) {
sentenceDetector = new SentenceDetectorME(new SentenceModel(modelIn));
} catch (Exception e) {
throw new IllegalStateException(”Sentence model missing”, e);
}
}
public Map<String, Object> computeStats(String text) {
Map<String, Object> stats = new LinkedHashMap<>();
String[] sentences = sentenceDetector.sentDetect(text);
int sentenceCount = sentences.length;
List<Integer> lengths = new ArrayList<>();
List<String> allTokens = new ArrayList<>();
for (String s : sentences) {
String[] tokens = tokenizer.tokenize(s);
allTokens.addAll(Arrays.asList(tokens));
lengths.add(tokens.length);
}
DescriptiveStatistics ds = new DescriptiveStatistics();
lengths.forEach(ds::addValue);
double meanLen = ds.getMean();
double burstiness = ds.getStandardDeviation();
double lexicalDiversity = new HashSet<>(allTokens).size() / (double) allTokens.size();
stats.put(”sentences”, sentenceCount);
stats.put(”mean_sentence_length”, meanLen);
stats.put(”burstiness”, burstiness);
stats.put(”lexical_diversity”, lexicalDiversity);
// Word frequency for common AI markers and phrases
List<String> aiWords = List.of(
“overall”, “moreover”, “additionally”, “furthermore”, “consequently”,
“nevertheless”, “therefore”, “thus”, “hence”, “indeed”, “notably”,
“crucial”, “paramount”, “essential”, “vital”, “significant”, “important”,
“delve”, “explore”, “navigate”, “unveil”, “unravel”, “comprehensive”,
“intricate”, “complexities”, “nuances”, “facets”, “realm”, “landscape”,
“tapestry”, “mosaic”, “journey”, “endeavor”, “pursuit”, “quest”
);
long aiHits = allTokens.stream()
.map(String::toLowerCase)
.filter(aiWords::contains)
.count();
stats.put(”ai_signal_terms”, aiHits);
// Simple perplexity proxy (variance of word length)
DescriptiveStatistics wlen = new DescriptiveStatistics();
allTokens.forEach(t -> wlen.addValue(t.length()));
stats.put(”perplexity_proxy”, wlen.getStandardDeviation());
// Additional metrics for better detection
stats.put(”total_words”, allTokens.size());
stats.put(”unique_words”, new HashSet<>(allTokens).size());
// Check for repetitive patterns (AI often repeats structures)
long punctuationCount = text.chars().filter(ch -> ch == ‘.’ || ch == ‘,’ || ch == ‘;’ || ch == ‘:’).count();
stats.put(”punctuation_density”, punctuationCount / (double) Math.max(1, allTokens.size()));
return stats;
}
}This gives four useful metrics:
Mean sentence length: AI text tends to be smoother and more uniform.
Burstiness (variance): High variance = more human.
Lexical diversity: Unique words ÷ total words.
AI signal terms: Words that often appear in LLM output (like “overall” or “in conclusion”).
Make sure to download the en-sent.bin and move it into /src/main/resources/models/
Integrating with the Service Layer
src/main/java/com/example/service/AnalysisService.java:
package com.example.service;
import java.util.LinkedHashMap;
import java.util.Map;
import com.example.nlp.TextAnalyzer;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
@ApplicationScoped
public class AnalysisService {
@Inject
TextAnalyzer analyzer;
public Map<String, Object> analyze(String text) {
if (text == null || text.isBlank()) {
return Map.of(”error”, “No text provided”);
}
Map<String, Object> stats = analyzer.computeStats(text);
int sentenceCount = (int) stats.get(”sentences”);
double meanSentenceLength = (double) stats.get(”mean_sentence_length”);
double burstiness = (double) stats.get(”burstiness”);
double diversity = (double) stats.get(”lexical_diversity”);
long aiWords = (long) stats.get(”ai_signal_terms”);
double perplexityProxy = (double) stats.get(”perplexity_proxy”);
int totalWords = (int) stats.get(”total_words”);
double punctuationDensity = (double) stats.get(”punctuation_density”);
// Improved scoring heuristic
double aiScore = 0.0;
// 1. Burstiness: AI text tends to have low variation in sentence length
// For single sentence, use mean length as indicator instead
if (sentenceCount == 1) {
// Single long sentences are often AI-generated
if (meanSentenceLength > 15) {
aiScore += 0.25;
}
} else {
// Multiple sentences: low burstiness indicates AI
if (burstiness < 3.0) {
aiScore += 0.2;
}
}
// 2. Lexical diversity: AI often uses more repetitive vocabulary
// But for very short texts, this metric is unreliable
if (totalWords > 20) {
if (diversity < 0.4) {
aiScore += 0.2;
}
} else {
// For short texts, very high diversity (all unique words) can be suspicious
if (diversity > 0.9 && totalWords > 10) {
aiScore += 0.15;
}
}
// 3. AI signal terms: common phrases in AI-generated text
double aiWordRatio = aiWords / (double) Math.max(1, totalWords);
if (aiWords >= 1) {
aiScore += Math.min(0.3, aiWordRatio * 10);
}
// 4. Mean sentence length: AI often generates longer, more complex sentences
if (meanSentenceLength > 18) {
aiScore += 0.15;
}
// 5. Perplexity proxy: low variance in word length suggests AI
if (perplexityProxy < 2.5 && totalWords > 15) {
aiScore += 0.1;
}
// 6. Punctuation density: AI often uses more formal punctuation
if (punctuationDensity > 0.15) {
aiScore += 0.1;
}
// 7. Very short texts with high complexity are suspicious
if (totalWords < 30 && meanSentenceLength > 12) {
aiScore += 0.15;
}
// Normalize score to 0-1 range
aiScore = Math.max(0.0, Math.min(1.0, aiScore));
String label = aiScore > 0.5 ? “AI-like” : “Human-like”;
Map<String, Object> result = new LinkedHashMap<>(stats);
result.put(”ai_score”, aiScore);
result.put(”classification”, label);
return result;
}
}Now you can POST any text to /api/detect and get a JSON result with metrics.
Start your application with:
quarkus devExample request:
curl -X POST http://localhost:8080/api/detect \
-H "Content-Type: application/json" \
-d '{"text": "In today’s fast-paced digital world, it is crucial to understand the complexities of Quarkus"}'Expected output:
{
“sentences”: 1,
“mean_sentence_length”: 19.0,
“burstiness”: 0.0,
“lexical_diversity”: 1.0,
“ai_signal_terms”: 2,
“perplexity_proxy”: 3.2190950746157228,
“total_words”: 19,
“unique_words”: 19,
“punctuation_density”: 0.05263157894736842,
“ai_score”: 1.0,
“classification”: “AI-like”
}Semantic Analysis with LangChain4j
Statistical signals work only up to a point. To check semantic similarity, we’ll embed the text and compare it to known human and AI writing samples.
Embedding Service
src/main/java/com/example/service/EmbeddingService.java:
package com.example.service;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.store.embedding.CosineSimilarity;
import dev.langchain4j.model.embedding.EmbeddingModel;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import java.util.*;
@ApplicationScoped
public class EmbeddingService {
@Inject
EmbeddingModel model;
private final Map<String, Embedding> reference = new HashMap<>();
public void initReference() {
reference.put(”human”, model.embed(”A deeply personal reflection on growing up by the ocean.”).content());
reference.put(”ai”, model.embed(”This article highlights the importance of artificial intelligence in modern society.”).content());
}
public double compare(String text) {
if (reference.isEmpty()) initReference();
Embedding input = model.embed(text).content();
double simHuman = CosineSimilarity.between(input, reference.get(”human”));
double simAI = CosineSimilarity.between(input, reference.get(”ai”));
return simAI - simHuman; // >0 = closer to AI
}
}Combine with Statistical Results
Add to AnalysisService:
@Inject
EmbeddingService embedding;
public Map<String, Object> analyze(String text) {
// ... existing steps
// 8. Semantic embedding analysis: compare text similarity to AI vs human reference texts
double semanticBias = embedding.compare(text);
if (semanticBias > 0) {
// Text is semantically closer to AI reference
aiScore += 0.2;
} else {
// Text is semantically closer to human reference
aiScore -= 0.1;
}
}Practical Ensemble and Dashboard
Let’s create a brief endpoint to serve the qute dashboard:
src/main/java/com/example/api/IndexResource.java:
package com.example.api;
import java.text.DecimalFormat;
import java.util.LinkedHashMap;
import java.util.Map;
import com.example.service.AnalysisService;
import io.quarkus.qute.Template;
import io.quarkus.qute.TemplateInstance;
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.FormParam;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
@Path(”/”)
public class IndexResource {
private static final DecimalFormat DF_2 = new DecimalFormat(”#0.00”);
private static final DecimalFormat DF_1 = new DecimalFormat(”#0.0”);
@Inject
Template index;
@Inject
AnalysisService service;
@GET
@Produces(MediaType.TEXT_HTML)
public TemplateInstance get() {
return index.data(”result”, null).data(”text”, “”);
}
@POST
@Consumes(MediaType.APPLICATION_FORM_URLENCODED)
@Produces(MediaType.TEXT_HTML)
public TemplateInstance analyze(@FormParam(”text”) String text) {
if (text == null || text.isBlank()) {
return index.data(”result”, null).data(”text”, text != null ? text : “”);
}
Map<String, Object> result = service.analyze(text);
Map<String, Object> formattedResult = formatResult(result);
return index.data(”result”, formattedResult).data(”text”, text);
}
private Map<String, Object> formatResult(Map<String, Object> result) {
Map<String, Object> formatted = new LinkedHashMap<>(result);
// Keep raw score for progress bar calculation
Double rawScore = result.get(”ai_score”) instanceof Double ? (Double) result.get(”ai_score”) : null;
if (rawScore != null) {
formatted.put(”ai_score_raw”, rawScore);
formatted.put(”ai_score_percent”, (int) (rawScore * 100));
}
// Format double values for display
if (result.get(”ai_score”) instanceof Double) {
formatted.put(”ai_score”, DF_2.format((Double) result.get(”ai_score”)));
}
if (result.get(”mean_sentence_length”) instanceof Double) {
formatted.put(”mean_sentence_length”, DF_1.format((Double) result.get(”mean_sentence_length”)));
}
if (result.get(”burstiness”) instanceof Double) {
formatted.put(”burstiness”, DF_2.format((Double) result.get(”burstiness”)));
}
if (result.get(”lexical_diversity”) instanceof Double) {
formatted.put(”lexical_diversity”, DF_2.format((Double) result.get(”lexical_diversity”)));
}
if (result.get(”punctuation_density”) instanceof Double) {
formatted.put(”punctuation_density”, DF_2.format((Double) result.get(”punctuation_density”)));
}
if (result.get(”semantic_bias”) instanceof Double) {
formatted.put(”semantic_bias”, DF_2.format((Double) result.get(”semantic_bias”)));
}
if (result.get(”perplexity_proxy”) instanceof Double) {
formatted.put(”perplexity_proxy”, DF_2.format((Double) result.get(”perplexity_proxy”)));
}
return formatted;
}
}Finally, the Qute page
src/main/resources/templates/index.qute.html:
<!DOCTYPE html>
<html lang=”en”>
<head>
<meta charset=”utf-8”>
<meta name=”viewport” content=”width=device-width, initial-scale=1.0”>
<title>AI Writing Detector</title>
<style>
<!-- omitted -->
</style>
</head>
<body>
<div class=”container”>
<h1>AI Writing Detector</h1>
<div class=”card”>
<form action=”/” method=”post”>
<textarea name=”text” rows=”10” placeholder=”Paste or type text here to analyze...”>{text}</textarea>
<br>
<button type=”submit”>🔍 Analyze Text</button>
</form>
</div>
{#if result}
<div class=”card”>
<div class=”result-header”>
<div>
{#if result.classification == ‘AI-like’}
<div class=”classification ai-like”>
{result.classification}
</div>
{#else}
<div class=”classification human-like”>
{result.classification}
</div>
{/if}
</div>
<div class=”score-container”>
<div class=”score-label”>AI Score</div>
<div class=”score-value”>{result.ai_score}</div>
</div>
</div>
{#if result.ai_score_percent}
<div class=”progress-bar”>
<div class=”progress-fill” style=”width: {result.ai_score_percent}%”>
{result.ai_score_percent}%
</div>
</div>
{/if}
<div class=”metrics-grid”>
<div class=”metric-card”>
<div class=”metric-label”>Sentences</div>
<div class=”metric-value”>{result.sentences}</div>
</div>
<div class=”metric-card”>
<div class=”metric-label”>Mean Sentence Length</div>
<div class=”metric-value”>{result.mean_sentence_length}</div>
</div>
<div class=”metric-card”>
<div class=”metric-label”>Burstiness</div>
<div class=”metric-value”>{result.burstiness}</div>
</div>
<div class=”metric-card”>
<div class=”metric-label”>Lexical Diversity</div>
<div class=”metric-value”>{result.lexical_diversity}</div>
</div>
<div class=”metric-card”>
<div class=”metric-label”>AI Signal Terms</div>
<div class=”metric-value”>{result.ai_signal_terms}</div>
</div>
<div class=”metric-card”>
<div class=”metric-label”>Total Words</div>
<div class=”metric-value”>{result.total_words}</div>
</div>
<div class=”metric-card”>
<div class=”metric-label”>Unique Words</div>
<div class=”metric-value”>{result.unique_words}</div>
</div>
<div class=”metric-card”>
<div class=”metric-label”>Punctuation Density</div>
<div class=”metric-value”>{result.punctuation_density}</div>
</div>
</div>
{#if result.semantic_bias}
{#if result.semantic_bias > 0}
<div class=”semantic-bias positive”>
<div class=”semantic-label”>Semantic Bias</div>
<div class=”semantic-value”>
→ Closer to AI reference ({result.semantic_bias})
</div>
</div>
{#else}
<div class=”semantic-bias negative”>
<div class=”semantic-label”>Semantic Bias</div>
<div class=”semantic-value”>
→ Closer to Human reference ({result.semantic_bias})
</div>
</div>
{/if}
{/if}
</div>
{/if}
</div>
</body>
</html>
If you use example text from Bert Brecht (clearly human) you will get a human like response. If you copy the first paragraph of this text, the Semantic bias is closer to AI while the static analysis does still say it is “human-like”.
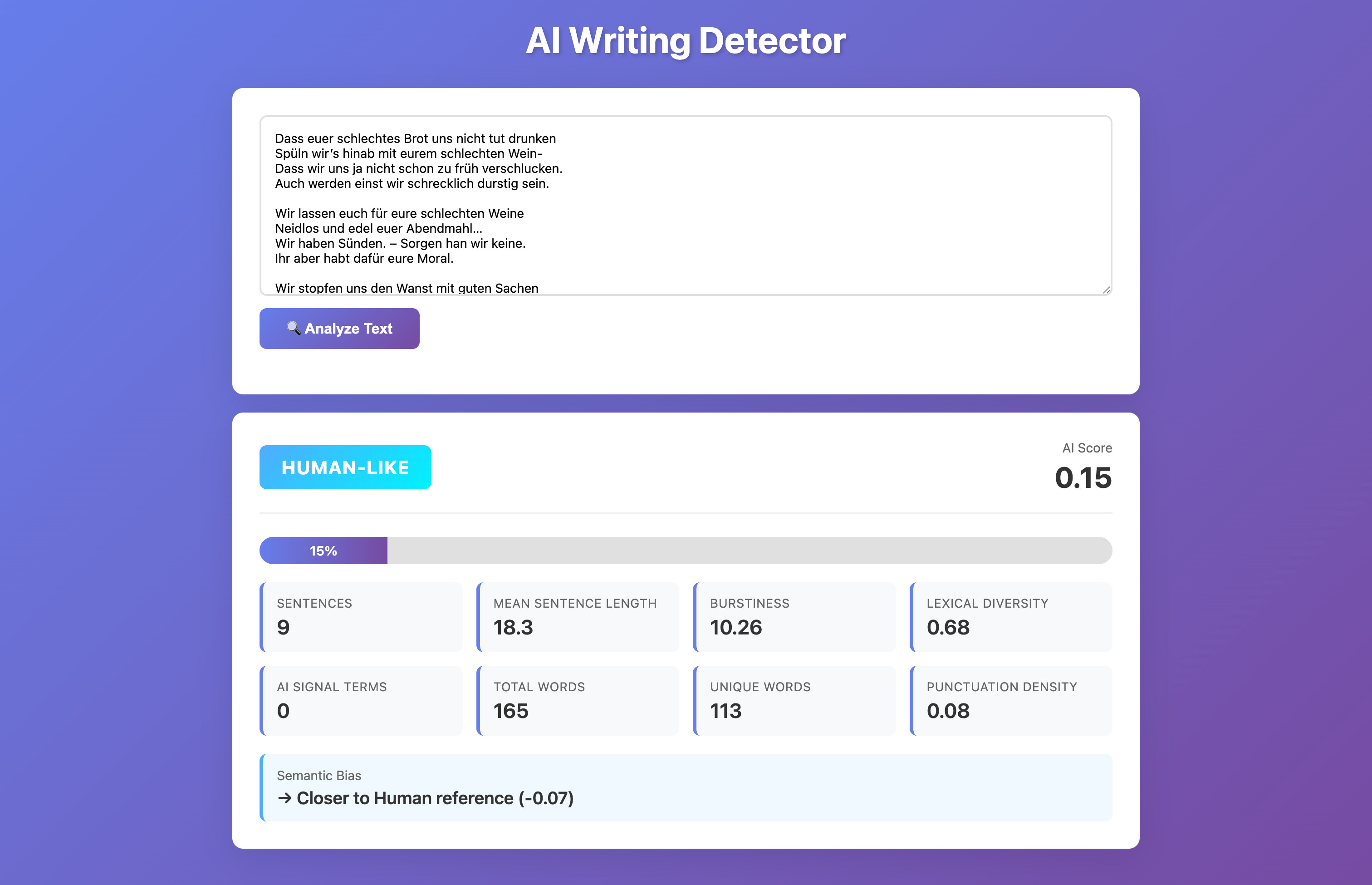
What You’ve Built
A Quarkus-based analysis API
A statistical signal detector using OpenNLP and commons-math
A semantic comparison using local embeddings via LangChain4j
Key Lessons
Statistical cues degrade over time. LLMs adapt quickly.
Perplexity and burstiness still help as rough heuristics.
Local embedding comparison offers privacy and speed.
So, you do write with AI?!
In the end, this little experiment reminded me why I write in the first place. Yes — I use AI every day. It helps me brainstorm titles, format code, catch typos, and occasionally challenge my assumptions. But every article here, including this one, still takes hours of technical verification, rewriting, and plain human stubbornness to get right. Building this detector didn’t make me paranoid about being “accused” again; it made me appreciate the blur between tool and author. What matters isn’t whether a model helped — it’s whether the work stands on truth, accuracy, and intent. And that part, at least, is still unmistakably human.
Olá Markus, tudo bem? Recentemente comecei meu substack inspirado no excelente trabalho que você faz aqui no substack. Eu acredito que este post pode ter sido direcionado a minha pessoa já que recentemente coloquei como recomendação no meu substack o The Main Thread. O ponto (caso este post pode ter sido direcionado ao que escrevi quando indiquei seu conteúdo) é que tenha interpretado errado o que escrevi devido a barreira linguística.
Na minha indicação comentei o uso da IA em relação ao seu post : "Mastery in the Age of Autocomplete: Lessons from 250 Days of Writing with AI" onde na minha interpretação diz como ela a IA te ajudou a fazer estes posts e não que ela fez para você. Caso seja isso, peço desculpas por ter interpretado que eu te "acusei" de algo. Simplesmente quis dizer que a IA, se bem ultizada, pode no tornar muito produtivo e fazer coisas muito boas como o trabalho que faz aqui.
Escrevi propositalmente na minha lingua nativa para que alguém que seja brasileiro e domine o inglês melhor que eu, possa esclarecer este comentário .
Meu inglês é ainda é "raso" e a idéia era auxiliar devs (principalmente juniors igual eu) a ter acesso a conteúdos do nível que você produz Markus.
Mais uma vez, peço desculpas caso tenha sido pelo que eu escrevi quando indiquei seu substack (que aliás consumo religiosamente as 6 da manhã todos os dias)