

Predicting NFL Games with Java: A Full ML Microservice Built on Quarkus
How I used real NFL data, Tribuo, and Quarkus to build a complete machine-learning pipeline from ingestion to prediction.


I’ll be honest: I don’t watch a lot of sports. I’ve never been the “Sunday Night Football” person, and I can’t name any players on an NFL roster or even German Fußball leagues. But if you give me a messy dataset full of historical matchups, win probabilities, point spreads, home-field advantage, and years of game outcomes?
Now I’m interested.
Sports may not be my thing as entertainment, but they are a fantastic playground for predictive analysis. Few domains produce clean, structured, highly granular time-series data at the scale the NFL does. Every season gives you hundreds of games, thousands of plays, and a rich constellation of variables: home vs. away performance, scoring patterns, offensive and defensive efficiency, quarterback impact, injury reports, season momentum, and more. It’s data paradise for anyone who loves models more than mascots.
And that’s why this tutorial exists.
In this walkthrough, you’ll build a complete NFL game outcome predictor using Java 21, Quarkus, PostgreSQL, and Tribuo, Oracle’s machine-learning library for the JVM. No Python. No Jupyter notebooks. Just clean, modern Java running a full ingestion pipeline that pulls real NFL data from ESPN’s public API, stores it locally, engineers features, trains a classifier, and serves predictions through a web interface.
Even if you don’t care about the Super Bowl, the playoffs, the AFC or NFC standings, or who’s leading the league in points this season, you’ll appreciate the engineering challenge. Sports prediction is a high-signal, fast-feedback environment. Models break, adjust, and improve every single week. The rules stay consistent, but the outcomes are chaotic. It’s the perfect testbed for building practical ML-infused microservices.
By the end of this tutorial, you’ll have:
A reproducible data pipeline for pulling NFL scoreboard data
A PostgreSQL-backed history of games and teams
A feature engineering layer for model training
A Tribuo logistic regression model that predicts home-win probabilities
A REST + Qute UI for browsing upcoming matchups and predicted outcomes
This is modern Java development meeting real-world analytics. Even if you’re not an NFL fan, you’ll walk away with a deeper understanding of how to embed machine learning into everyday microservices—using tools you already know.
Let’s build something smarter than a typical game-day hot take.
Prerequisites
Java 21+
Maven 3.8+
Podman or Docker
PostgreSQL
Basic REST knowledge
Project Setup
Create the Quarkus project or grab the source from my Github repository.
mvn io.quarkus:quarkus-maven-plugin:create \
-DprojectGroupId=com.nfl.predictor \
-DprojectArtifactId=nfl-game-predictor \
-DclassName="com.nfl.predictor.resource.AdminResource" \
-Dpath="/api/admin" \
-Dextensions="rest-jackson,hibernate-orm-panache,jdbc-postgresql,rest-client-jackson,rest-qute,qute"
cd nfl-game-predictorAdd Tribuo Dependencies
Add to pom.xml:
<dependencies>
<!-- Tribuo ML Dependencies -->
<dependency>
<groupId>org.tribuo</groupId>
<artifactId>tribuo-classification-core</artifactId>
<version>4.3.2</version>
</dependency>
<dependency>
<groupId>org.tribuo</groupId>
<artifactId>tribuo-classification-xgboost</artifactId>
<version>4.3.2</version>
</dependency>
<dependency>
<groupId>org.tribuo</groupId>
<artifactId>tribuo-classification-sgd</artifactId>
<version>4.3.2</version>
</dependency>
<build>
<plugins>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.5.4</version>
<configuration>
<argLine>--add-opens java.base/java.lang=ALL-UNNAMED</argLine>
</configuration>
</plugin>
</plugins>
</build>
Important: Tribuo requires --add-opens with Java 21.
Application Configuration
src/main/resources/application.properties:
# Database
quarkus.datasource.db-kind=postgresql
quarkus.hibernate-orm.schema-management.strategy=drop-and-create
# ESPN API Configuration
# Using unofficial ESPN API: https://github.com/pseudo-r/Public-ESPN-API
# Base URL: http://site.api.espn.com/apis/site/v2
# Note: This is an unofficial, undocumented API that may change without notice
quarkus.rest-client.espn-api.url=http://site.api.espn.com/apis/site/v2
quarkus.rest-client.espn-api.scope=jakarta.inject.Singleton
%dev.quarkus.datasource.dev-ui.allow-sql=trueESPN API Integration
REST Client
Create the com/nfl/predictor/client/ESPNClient.java
@RegisterRestClient(configKey = “espn-api”)
@Path(”/sports/football/nfl”)
public interface ESPNClient {
@GET
@Path(”/scoreboard”)
ESPNScoreboardResponse getScoreboard(@QueryParam(”dates”) String dates);
@GET
@Path(”/teams”)
ESPNTeamsResponse getTeams();
}
JSON structures vary. DTOs use @JsonIgnoreProperties to stay resilient.
Database Entities
Create the Team Entity com/nfl/predictor/entity/Team.java
@Entity
@Table(name = “teams”)
public class Team extends PanacheEntity {
@Column(unique = true)
public String espnId;
public String name;
public String abbreviation;
public Integer wins = 0;
public Integer losses = 0;
public Integer pointsScored = 0;
public Integer pointsAllowed = 0;
public double getWinPercentage() {
int played = wins + losses;
return played > 0 ? (double) wins / played : 0.5;
}
public double getAveragePointsScored() { … }
public double getAveragePointsAllowed() { … }
}
Create the Game Entity com/nfl/predictor/entity/Game.java
@Entity
@Table(name = “games”)
public class Game extends PanacheEntity {
@Column(unique = true)
public String espnId;
@ManyToOne public Team homeTeam;
@ManyToOne public Team awayTeam;
public LocalDateTime gameDate;
public Integer homeScore;
public Integer awayScore;
public Boolean completed = false;
public Double predictedHomeWinProbability;
public Boolean predictedHomeWin;
public boolean wasHomeWin() {
return completed && homeScore > awayScore;
}
}
Machine Learning with Tribuo
This project uses a fully Java-based ML pipeline:
Extract structured numeric features.
Train a model using Tribuo.
Serialize the model to disk.
Load the model at runtime.
Predict outcomes for upcoming games.
Feature Engineering
Tribuo models operate on numerical features.
Your feature vector includes:
Win percentages
Average points scored
Average points allowed
Home advantage
Label:
“HOME_WIN”or“AWAY_WIN”
TrainingExample Record
package com.nfl.predictor.ml;
public record TrainingExample(
double homeWinPct,
double awayWinPct,
double homeAvgPointsScored,
double awayAvgPointsScored,
double homeAvgPointsAllowed,
double awayAvgPointsAllowed,
double homeAdvantage,
String label // “HOME_WIN” or “AWAY_WIN”
) {
}Feature Builder
The FeatureBuilder (src/main/java/com/nfl/predictor/ml/FeatureBuilder.java) is the main component that transforms raw game data into numeric features that machine learning models can understand. Here’s what it does:
Machine learning models can’t work with raw objects like “Team” or “Game” - they need numbers. The FeatureBuilder converts game information into a structured set of numeric features.
These features capture the essential information that predicts game outcomes:
Win percentage shows overall team quality
Points scored measures offensive capability
Points allowed measures defensive capability
Home advantage accounts for the statistical edge home teams have
The ML model learns patterns from these features across hundreds of games to make predictions for future matchups.
@ApplicationScoped
public class FeatureBuilder {
public TrainingExample fromGame(Game g) {
return new TrainingExample(
g.homeTeam.getWinPercentage(),
g.awayTeam.getWinPercentage(),
g.homeTeam.getAveragePointsScored(),
g.awayTeam.getAveragePointsScored(),
g.homeTeam.getAveragePointsAllowed(),
g.awayTeam.getAveragePointsAllowed(),
1.0,
g.wasHomeWin() ? “HOME_WIN” : “AWAY_WIN”
);
}
public List<TrainingExample> buildTrainingSet(List<Game> completedGames) {
return completedGames.stream().map(this::fromGame).toList();
}
}
Model Training
The ModelTrainer is responsible for training, saving, and loading the machine learning model. It handles the complete lifecycle of the prediction model - from training on historical data to persisting it for future use.
@ApplicationScoped
@RegisterForReflection(targets = { Model.class })
public class ModelTrainer {
@Inject
FeatureBuilder featureBuilder;
private static final String MODEL_PATH = “model.nfl”;
public Model<Label> train(List<Game> games) throws Exception {
List<TrainingExample> rows = featureBuilder.buildTrainingSet(games);
LabelFactory labels = new LabelFactory();
List<Example<Label>> examples = new ArrayList<>();
for (var r : rows) {
Example<Label> ex = new ArrayExample<>(
new Label(r.label()),
new String[] {
“homeWinPct”,”awayWinPct”,
“homeAvgScored”,”awayAvgScored”,
“homeAvgAllowed”,”awayAvgAllowed”,
“homeAdvantage”
},
new double[] {
r.homeWinPct(), r.awayWinPct(),
r.homeAvgPointsScored(), r.awayAvgPointsScored(),
r.homeAvgPointsAllowed(), r.awayAvgPointsAllowed(),
r.homeAdvantage()
}
);
examples.add(ex);
}
var provenance = new SimpleDataSourceProvenance(”NFL Games”, null);
var dataset = new MutableDataset<>(examples, provenance, labels);
var trainer = new LogisticRegressionTrainer();
Model<Label> model = trainer.train(dataset);
saveModel(model);
return model;
}
public void saveModel(Model<Label> m) throws Exception {
m.serializeToFile(Paths.get(MODEL_PATH));
}
public Model<Label> loadModel() throws Exception {
return (Model<Label>) Model.deserializeFromFile(Paths.get(MODEL_PATH));
}
}
Training: Called by
AdminResource.trainModel()when you hitGET /api/admin/model/trainLoading: Called by
ModelInferenceto load the model for making predictionsPersistence: The model survives application restarts - train once, predict many times
Model Inference
The ModelInference is responsible for using the trained ML model to make predictions on upcoming games. It takes a game (with two teams) and predicts which team will win, along with the probability of that outcome.
@ApplicationScoped
public class ModelInference {
@Inject FeatureBuilder builder;
@Inject ModelTrainer trainer;
private Model<Label> model;
private void ensureModelLoaded() throws Exception {
if (model == null) model = trainer.loadModel();
}
public record PredictionResult(double homeWinProbability, boolean homeWinPredicted) {}
public PredictionResult predict(Game game) throws Exception {
ensureModelLoaded();
var f = builder.fromGame(game);
Example<Label> ex = new ArrayExample<>(
null,
new String[] {
“homeWinPct”,”awayWinPct”,
“homeAvgScored”,”awayAvgScored”,
“homeAvgAllowed”,”awayAvgAllowed”,
“homeAdvantage”
},
new double[] {
f.homeWinPct(), f.awayWinPct(),
f.homeAvgPointsScored(), f.awayAvgPointsScored(),
f.homeAvgPointsAllowed(), f.awayAvgPointsAllowed(),
f.homeAdvantage()
}
);
var prediction = model.predict(ex);
var scores = prediction.getOutputScores();
var homeScore = scores.get(”HOME_WIN”);
double prob = homeScore != null ? homeScore.getScore() : 0.5;
return new PredictionResult(prob, prob > 0.5);
}
}
The complete training and inference flow:

Admin API
A simple rest endpoint to get the main results from the application.
/api/admin provides:
GET /teams— list all teamsGET /games— list all gamesGET /model/train— train the Tribuo modelGET /model/status— check if model is trainedGET /predictions— get predictions for upcoming games
Upcoming Games UI (Qute)
The Qute UI provides a polished, NFL-themed web interface for viewing game predictions.
@Path(”/upcoming-games”)
public class UpcomingGamesResource {
@Inject ModelInference inference;
@Inject
@Location(”upcoming-games.html”)
Template template;
@GET
@Produces(MediaType.TEXT_HTML)
@Transactional
public TemplateInstance get(@QueryParam(”page”) @DefaultValue(”0”) int page) {
List<Game> upcoming = Game.find(
“completed = false and gameDate > ?1 order by gameDate”,
LocalDateTime.now()
).list();
for (var g : upcoming) {
if (g.predictedHomeWinProbability == null) {
var r = inference.predict(g);
g.predictedHomeWinProbability = r.homeWinProbability();
g.predictedHomeWin = r.homeWinPredicted();
g.persist();
}
}
// Pagination omitted for brevity...
return template.data(”games”, gamesForPage)
.data(”currentPage”, page)
.data(”totalPages”, totalPages);
}
}
Running the Application
Time to fire up the application.
Start Quarkus
./mvnw quarkus:devTry it out
Just navigate to http://localhost:8080/upcoming-games and take a look at the results.
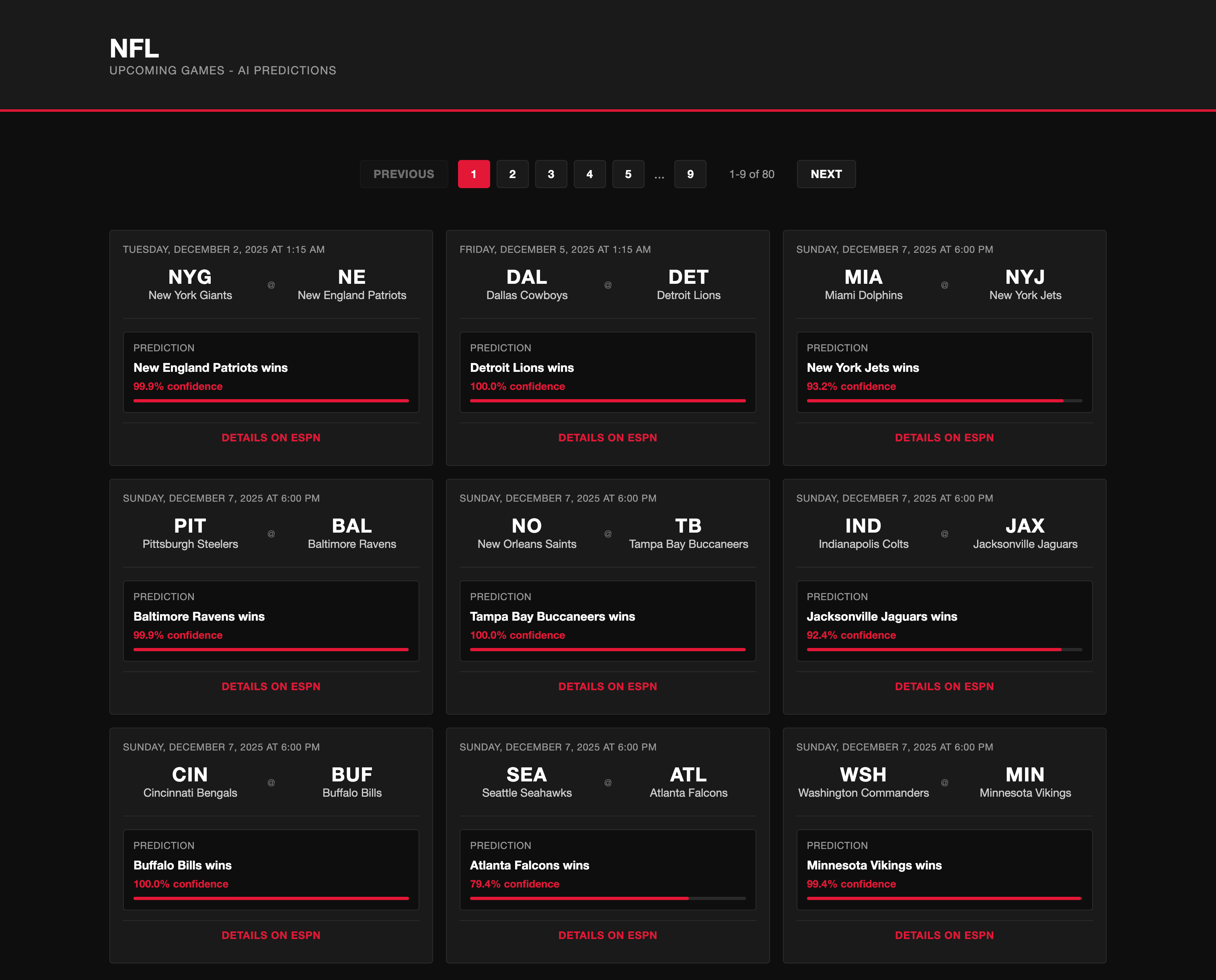
You can also use the admin endpoints:
Train the model:
curl http://localhost:8080/api/admin/model/trainSee predictions:
curl http://localhost:8080/api/admin/predictionsHow the App Uses the ESPN API (and Why We Pre-Load Data)
The application relies on ESPN’s unofficial public API to fetch real NFL game data. It provides flexible endpoints for scoreboards, team data, and historical results. Since it is undocumented and rate-limited, your Quarkus service is designed to use it sparingly and only when needed.
The app communicates with the API through a MicroProfile REST Client. The most important endpoint is the “scoreboard” endpoint, which returns a list of NFL games for a given date or date range.
Preloading Data with import.sql
Constantly hitting the ESPN API during development is slow and unnecessary.
To solve this, the application includes a pre-populated import.sql file containing:
All NFL teams
Hundreds of games from the current NFL season
Clean relational data ready for Panache entities
When Quarkus starts with schema generation set to drop-and-create, Hibernate automatically loads the data into your PostgreSQL database.
This gives you:
Instant startup
Zero external API calls during development
A consistent dataset to debug the ML pipeline
Repeatable results for feature engineering and training
Automatic Data Loading on Startup
If the database starts empty (e.g., in production or a fresh environment), the application automatically fetches data from the ESPN API.
On startup:
Check if any games exist.
If not, fetch the previous season and the current season using large date ranges.
Store all games and teams locally.
Recalculate team statistics from completed games.
Train the Tribuo model immediately.
This means the system comes online fully ready—with games, teams, statistics, and a trained ML model without any manual steps.
Next Steps
Add richer features (weather, injuries, streaks)
Switch Tribuo to XGBoost for higher accuracy
Introduce Kafka for live updates
Track model accuracy over time
Add Redis for prediction caching
Build a native binary via GraalVM
Conclusion
You now have a fully functional NFL game predictor built entirely in Java:
Real ESPN data
PostgreSQL persistence
Feature engineering
Model training with Tribuo
Model serialization and inference
REST APIs and Qute UI
Quarkus scheduling and dev-mode tooling
A complete, modern ML microservice—no Python needed.
Awesome ! Perhaps just a missing line in the pom.xml listing, nothing serious.