

Building an AI-Powered PDF Processing Pipeline with Quarkus, Camel, and LangChain4j
Securely scan, extract, and summarize documents using ClamAV, Camel routes, and local LLMs with Ollama.


In this hands-on tutorial, you'll build a complete file processing pipeline in Java using Quarkus, Apache Camel, and LangChain4j. The pipeline accepts uploaded PDFs, scans them for viruses, extracts their content, and summarizes them using a local LLM served by Ollama. Thanks to the camel-langchain4j component, we can inject AI-powered analysis directly into our Camel route with zero boilerplate and just business logic.
What You’ll Build
This application does the following:
Accepts PDF file uploads using a non-blocking REST endpoint.
Scans each uploaded file using ClamAV to ensure it's virus-free.
Extracts raw text using
camel-pdf.Sends the text to a Large Language Model using the
camel-langchain4j-chatextension for summarization.Returns the summary to the user as a JSON response.
By the end, you’ll understand how to fuse traditional file processing with LLM-based automation securely.
Project Setup
Start by bootstrapping your Quarkus project with the right set of extensions.
mvn io.quarkus.platform:quarkus-maven-plugin:create \
-DprojectGroupId=com.example \
-DprojectArtifactId=pdf-processing-pipeline \
-Dextensions="rest-jackson, camel-quarkus-pdf, camel-quarkus-langchain4j,camel-quarkus-direct,camel-quarkus-langchain4j-chat,langchain4j-ollama, quarkus-antivirus"
cd pdf-processing-pipelineKey Dependencies:
rest-jackson: Provides fast, non-blocking REST endpoints.camel-quarkus-pdf: Extracts text from PDF documents.camel-quarkus-langchain4j: Integrates LangChain4j into Camel routes.camel-quarkus-langchain4j-chat: Gives Camel access to chat models.camel-quarkus-direct: Calls another endpoint from the same Camel Context synchronouslylangchain4j-ollama: Connects LangChain4j to Ollama and its local models.quarkus-antivirus: Wraps antivirus capabilities, e.g., ClamAV, for file scanning.
And as usual, feel free to grab the full example from my Github repository.
Configuration
Edit src/main/resources/application.properties:
# LangChain4j Ollama Configuration
quarkus.langchain4j.ollama.chat-model.model-id=gpt-oss:20b
# File Upload Configuration
quarkus.http.limits.max-body-size=50M
# Antivirus Configuration
quarkus.antivirus.clamav.enabled=trueThe application.properties file defines how the application runs: it configures a local Ollama model (gpt-oss:20b) for AI processing, sets a 50 MB upload limit so large PDF files can be accepted, and enables ClamAV antivirus scanning to check files before processing. Together, these settings ensure that the service can securely handle and analyze sizable PDFs while protecting against malware.
Virus Scanning Bean
Create a new Java class VirusScanner.java in src/main/java/com/example. This bean injects the Antivirus service and provides a simple method we can call from our Camel route.
package com.example;
import java.io.ByteArrayInputStream;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.List;
import io.quarkiverse.antivirus.runtime.Antivirus;
import io.quarkiverse.antivirus.runtime.AntivirusScanResult;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import jakarta.inject.Named;
@ApplicationScoped
@Named("virusScanner")
public class VirusScanner {
@Inject
Antivirus antivirus;
public byte[] scan(Path filePath) throws Exception {
// Scan the file
byte[] fileBytes = Files.readAllBytes(filePath);
try (var inputStream = new ByteArrayInputStream(fileBytes)) {
List<AntivirusScanResult> results = antivirus.scan(filePath.toString(), inputStream);
for (AntivirusScanResult result : results) {
if (result.getStatus() != 200) {
throw new Exception("Virus found: " + result.getMessage());
}
}
}
return fileBytes; // Return the file content instead of path
}
}The VirusScanner class serves as a security checkpoint in the pipeline: it takes uploaded files, wraps their bytes in a ByteArrayInputStream, and passes that stream to the ClamAV antivirus scanner. This design follows the Quarkus antivirus API contract, which expects an InputStream, and lets the scanner process data efficiently in chunks instead of as a single byte array. If a threat is detected, the class raises a Exception; if not, the clean content is returned for further processing.
We also use the @Named annotation to make the bean available to the Camel route.
Reactive File Upload Endpoint
The FileUploadResource class is the REST entry point for the PDF pipeline. It exposes a POST /upload endpoint that accepts multipart form data, validates that a non-null PDF file was provided, and rejects invalid input with a 400 response. Valid files are passed as File objects into the Camel route via a ProducerTemplate, targeting the direct:processPdf endpoint for downstream processing. The class handles errors gracefully: Failures are caught and reported as structured HTTP responses. In the overall architecture, it serves as the gateway, bridging HTTP requests with the Camel-driven PDF processing workflow.
Rename the scaffolded GreetingResource and add below code that accepts multipart file uploads and passes the file path to Camel.
src/main/java/com/example/FileUploadResource.java
package com.example;
import java.io.File;
import org.apache.camel.ProducerTemplate;
import org.jboss.resteasy.reactive.multipart.FileUpload;
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
@Path("/upload")
public class FileUploadResource {
@Inject
private ProducerTemplate producerTemplate;
@POST
@Consumes(MediaType.MULTIPART_FORM_DATA)
@Produces(MediaType.APPLICATION_JSON)
public Response uploadFile(@org.jboss.resteasy.reactive.RestForm FileUpload file) {
if (file == null || !file.fileName().toLowerCase().endsWith(".pdf")) {
return Response.status(Response.Status.BAD_REQUEST)
.entity("{\"error\":\"A PDF file must be uploaded\"}")
.build();
}
try {
// Get the uploaded file directly
File uploadedFile = file.uploadedFile().toFile();
// Send the file path to the Camel route and get the result
String result = producerTemplate.requestBody("direct:processPdf", uploadedFile, String.class);
return Response.ok(result).build();
} catch (Exception e) {
return Response.status(Response.Status.INTERNAL_SERVER_ERROR)
.entity("{\"error\":\"Processing failed: " + e.getMessage() + "\"}")
.build();
}
}
}Key Features:
Validates that the file is a
.pdf.Sends the file path to Camel via the
direct:processPdfendpoint.Handles exceptions such as viruses or LLM failures gracefully.
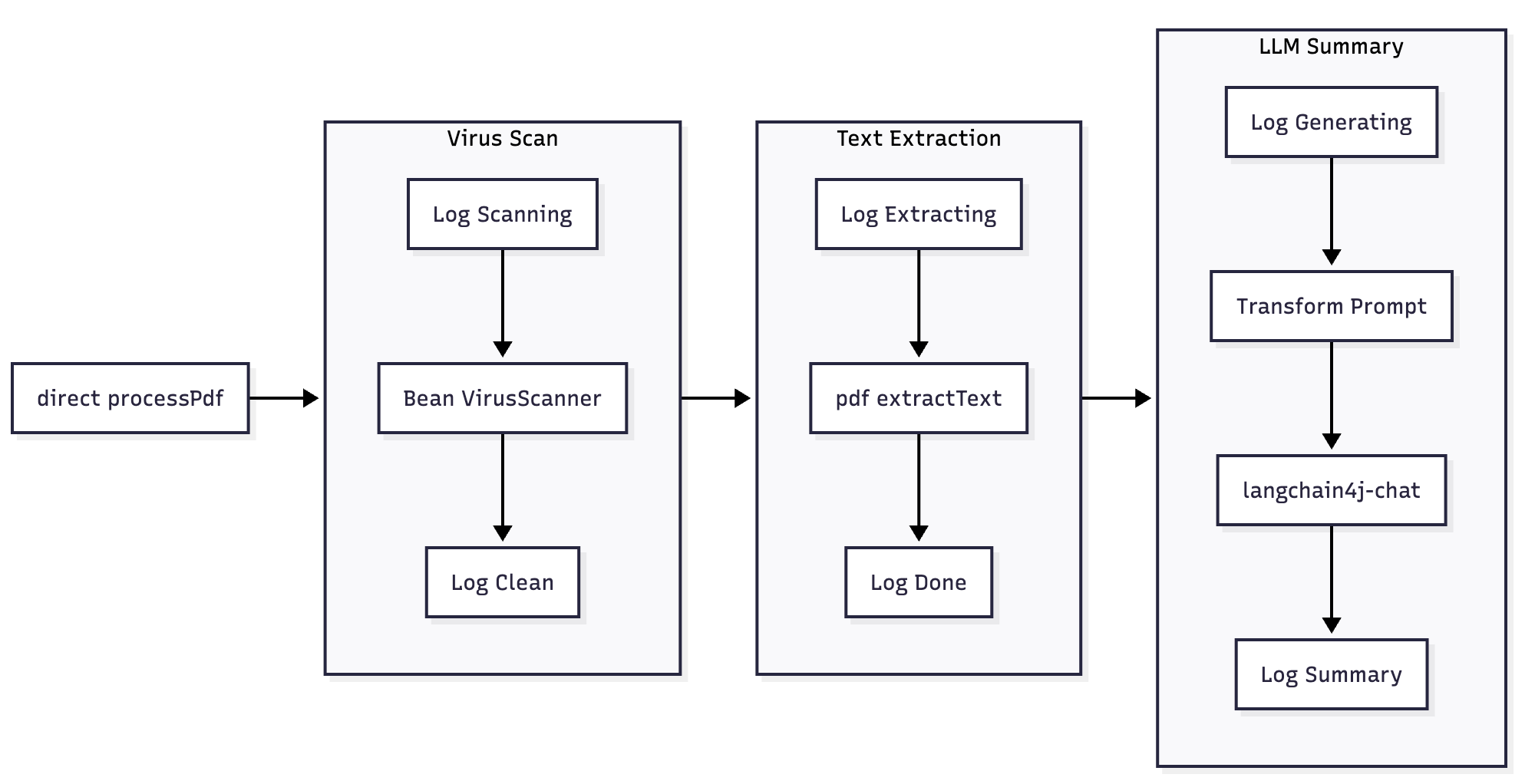
The Camel Route
This is the core of our pipeline where we define the processing flow. By using camel-langchain4j, we no longer need to create custom AI service beans. The route becomes simpler and more declarative.
Create the route in PdfProcessingRoute.java.
package com.example;
import org.apache.camel.LoggingLevel;
import org.apache.camel.builder.RouteBuilder;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
public class PdfProcessingRoute extends RouteBuilder {
@Override
public void configure() throws Exception {
// Global exception handling
onException(Exception.class)
.handled(true) // Mark as handled so it doesn't propagate
.log(LoggingLevel.ERROR, "Error processing file: ${exception.message}")
.setBody(constant("Error: File processing failed"))
.stop(); // Stop further processing
from("direct:processPdf")
.log("New PDF received: ${header.CamelMessageBodyType}")
.log("→ Scanning for viruses...")
.bean("virusScanner", "scan")
.log("✔ File is clean.")
.log("→ Extracting text...")
.to("pdf:extractText")
.log("✔ Extraction done. Text: ${body}")
.log("→ Generating summary via LLM...")
.transform(simple(
"Provide a concise, one-paragraph summary of the following text extracted from a PDF file: ${body}"))
.to("langchain4j-chat:default")
.log("✔ Summary complete: ${body}")
.transform(simple("PDF summary: ${body}"))
.log("✔ Basic processing complete: ${header.CamelMessageBodyType}");
}
}Key Features:
bean("virusScanner", "scan"): Scans the file.to("pdf:extractText"): Extracts raw text from PDF.transform(simple(...)): Crafts a prompt for the LLM.to("langchain4j-chat:default"): Sends the prompt to the LangChain4j Ollama-backed model.
This is a full declarative AI pipeline embedded directly in your Camel flow and no glue code, no clutter.
Running the App
Start Quarkus in dev mode:
./mvnw quarkus:devThen upload a PDF:
curl -v -X POST -F "file=@/path/to/document.pdf" http://localhost:8080/uploadYou’ll see detailed logs for each processing stage. If the document is clean, you’ll get a JSON response with the AI-generated summary. If it contains a virus, the system will fail fast and return an error.
Conclusion
This tutorial demonstrates how to build an AI-infused file processing pipeline in Java with Camel. By combining Quarkus with Apache Camel and LangChain4j, you can integrate modern LLM capabilities into your data flows without rewriting your architecture or drowning in boilerplate.
This setup is ideal for intelligent ingestion systems, secure knowledge workflows, or any use case where file uploads meet AI summarization and content automation.
Want to extend it? Add:
Semantic vector storage of extracted content.
Text classification or named entity recognition.
Human-in-the-loop workflows for flagged documents.
The future of enterprise Java isn’t just fast: It’s intelligent.
Thanks for this tutorial. I got a couple of dependency management errors, but have managed to solve with the the following pom:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>pdf-processing-pipeline</artifactId>
<version>1.0.0-SNAPSHOT</version>
<properties>
<compiler-plugin.version>3.14.0</compiler-plugin.version>
<maven.compiler.release>21</maven.compiler.release>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<quarkus.platform.artifact-id>quarkus-bom</quarkus.platform.artifact-id>
<quarkus.platform.group-id>io.quarkus.platform</quarkus.platform.group-id>
<quarkus.platform.version>3.29.0</quarkus.platform.version>
<skipITs>true</skipITs>
<surefire-plugin.version>3.5.2</surefire-plugin.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>${quarkus.platform.group-id}</groupId>
<artifactId>${quarkus.platform.artifact-id}</artifactId>
<version>${quarkus.platform.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>${quarkus.platform.group-id}</groupId>
<artifactId>quarkus-camel-bom</artifactId>
<version>${quarkus.platform.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-rest-jackson</artifactId>
</dependency>
<dependency>
<groupId>org.apache.camel.quarkus</groupId>
<artifactId>camel-quarkus-direct</artifactId>
</dependency>
<dependency>
<groupId>org.apache.camel.quarkus</groupId>
<artifactId>camel-quarkus-pdf</artifactId>
</dependency>
<dependency>
<groupId>org.apache.camel.quarkus</groupId>
<artifactId>camel-quarkus-langchain4j</artifactId>
<version>3.26.0</version>
</dependency>
<dependency>
<groupId>org.apache.camel.quarkus</groupId>
<artifactId>camel-quarkus-langchain4j-chat</artifactId>
<version>3.26.0</version>
</dependency>
<dependency>
<groupId>io.quarkiverse.antivirus</groupId>
<artifactId>quarkus-antivirus</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>io.quarkiverse.langchain4j</groupId>
<artifactId>quarkus-langchain4j-ollama</artifactId>
<version>1.4.0.CR2</version>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-arc</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-rest</artifactId>
</dependency>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-junit5</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>rest-assured</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>${quarkus.platform.group-id}</groupId>
<artifactId>quarkus-maven-plugin</artifactId>
<version>${quarkus.platform.version}</version>
<extensions>true</extensions>
<executions>
<execution>
<goals>
<goal>build</goal>
<goal>generate-code</goal>
<goal>generate-code-tests</goal>
<goal>native-image-agent</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>${compiler-plugin.version}</version>
<configuration>
<parameters>true</parameters>
</configuration>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>${surefire-plugin.version}</version>
<configuration>
<argLine>--add-opens java.base/java.lang=ALL-UNNAMED</argLine>
<systemPropertyVariables>
<java.util.logging.manager>org.jboss.logmanager.LogManager</java.util.logging.manager>
<maven.home>${maven.home}</maven.home>
</systemPropertyVariables>
</configuration>
</plugin>
<plugin>
<artifactId>maven-failsafe-plugin</artifactId>
<version>${surefire-plugin.version}</version>
<executions>
<execution>
<goals>
<goal>integration-test</goal>
<goal>verify</goal>
</goals>
</execution>
</executions>
<configuration>
<argLine>--add-opens java.base/java.lang=ALL-UNNAMED</argLine>
<systemPropertyVariables>
<native.image.path>${project.build.directory}/${project.build.finalName}-runner</native.image.path>
<java.util.logging.manager>org.jboss.logmanager.LogManager</java.util.logging.manager>
<maven.home>${maven.home}</maven.home>
</systemPropertyVariables>
</configuration>
</plugin>
</plugins>
</build>
<profiles>
<profile>
<id>native</id>
<activation>
<property>
<name>native</name>
</property>
</activation>
<properties>
<quarkus.package.jar.enabled>false</quarkus.package.jar.enabled>
<skipITs>false</skipITs>
<quarkus.native.enabled>true</quarkus.native.enabled>
</properties>
</profile>
</profiles>
</project>
In the above, I set the quarkus.platform.version to 3.29.0 and quarkus-langchain libs to version 3.26.0
Also, I had to use the llama3.2:latest model.
Hi Markus, thank you so much for the article. I have a PDF with a client's information in several sections (ID document, policy letter, policy, contract, and others), and they have different image and text scan formats. I need to split it into separate PDFs for each section. What process would you recommend, or how would you approach this?