

Building a Real-Time RSS Integration with Quarkus and Apache Camel
Learn how to stream, transform, and monitor RSS feeds using Camel DSL, Micrometer metrics, and Quarkus for production-ready Java integrations.


We will rebuild Spring’s “Integrating Data” starter in Quarkus using Apache Camel’s Java DSL. The route polls the Quarkus blog RSS feed, splits entries, transforms them to a POJO, writes newline-delimited JSON, and exposes an optional REST endpoint to read recent items.
Camel gives you a stable DSL and connectors. Quarkus gives you fast dev loops and production efficiency. Together they make small, reliable integration services.
Prerequisites
JDK 21
Maven 3.9+ or the Quarkus CLI installed (
quarkus --version)
Project bootstrap
quarkus create app org.acme:camel-rss-quarkus:1.0.0 \
-x "camel-quarkus-rss,camel-quarkus-file,camel-quarkus-log,camel-quarkus-jackson,camel-quarkus-direct,quarkus-rest-jackson,camel-quarkus-micrometer"
cd camel-rss-quarkusWhy these extensions:
camel-quarkus-rssto poll and parse RSS.camel-quarkus-jacksonfor JSON.camel-quarkus-fileto write to disk.camel-quarkus-logfor quick visibility.quarkus-rest-jacksonfor the tiny verification endpoint.camel-quarkus-micrometerfor health metrics
Just wanna take a sneak peak at the code? Look at the example Github repository.
Configuration
We keep the source and sink URIs in properties. This makes the route easy to test by swapping endpoints.
# src/main/resources/application.properties
# output location for newline-delimited JSON
app.out.dir=target/out
app.out.filename=quarkus-feed.jsonl
# default source and sink for real runs
app.source.uri=rss:https://quarkus.io/feed.xml
app.sink.uri=file:${app.out.dir}?fileName=${app.out.filename}&fileExist=Append
# logs
quarkus.log.category.”org.apache.camel”.level=INFO
quarkus.log.console.json=falseDomain model
// src/main/java/org/acme/rss/FeedItem.java
package org.acme.rss;
import java.time.OffsetDateTime;
public record FeedItem(
String title,
String link,
String author,
OffsetDateTime published
) {}
Short, immutable, JSON-friendly.
The Camel route (Java DSL)
The RssRoute defines a complete RSS processing workflow that polls feeds, processes them through the processor, and forwards the results to a destination while collecting metrics along the way.
package org.acme.rss;
import com.fasterxml.jackson.databind.*;
import jakarta.enterprise.context.*;
import jakarta.inject.*;
import org.acme.rss.processors.*;
import org.apache.camel.builder.*;
import org.apache.camel.component.jackson.*;
@ApplicationScoped
public class RssRoute extends RouteBuilder {
@Inject
ObjectMapper mapper;
@Inject
RssFeedProcesor rssFeedProcessor;
@Override
public void configure() {
JacksonDataFormat json = new JacksonDataFormat(mapper, FeedItem.class);
from(”{{app.source.uri}}?splitEntries=false&delay=60000”)
.routeId(”quarkus-rss-poller”)
.log(”Fetched RSS feed: ${body}”)
.process(rssFeedProcessor)
.log(”Finished processing feed”);
from(”direct:processEntry”)
.marshal(json)
.convertBodyTo(String.class)
.setBody(simple(”${body}”))
.transform(body()
.append(”\n”))
.toD(”{{app.sink.uri}}”)
.to(”micrometer:counter:rss_items_total?tags=author=${header.author},month=${header.month}”);
}
}RSS Polling Route: Sets up a scheduled route that polls an RSS feed source every 60 seconds (configurable via app.source.uri property)
Feed Processing Pipeline: Routes incoming RSS feeds through the RssFeedProcesor to handle deduplication and transformation
Entry Processing Route: Creates a separate route (direct:processEntry) that handles individual RSS entries after they’ve been processed
JSON Serialization: Converts FeedItem objects to JSON format using Jackson ObjectMapper for data interchange
Data Forwarding: Sends processed RSS entries to a configurable sink destination (app.sink.uri property)
Metrics Collection: Records processing metrics using Micrometer, tracking total RSS items processed with tags for author and month
Logging: Provides visibility into the RSS fetching and processing workflow with appropriate log messages
Configuration-Driven: Uses external configuration properties for source and sink URIs, making the route flexible for different environments
Dependency Injection: Leverages Quarkus CDI to inject required dependencies (ObjectMapper and RssFeedProcessor)
A note of thanks to @Nicolas Duminil. He was so kind to send a PR where he extracted the RSS parsing logic into a separate Processor.
The Feed Item Processor
The RssFeedProcesor acts as a deduplication and transformation layer in an RSS processing pipeline, ensuring each feed item is processed only once and forwarded to downstream processing with enriched metadata.
package org.acme.rss.processors;
import java.time.OffsetDateTime;
import java.time.ZoneOffset;
import java.time.format.DateTimeFormatter;
import java.util.Map;
import java.util.Optional;
import java.util.Set;
import java.util.concurrent.ConcurrentHashMap;
import org.acme.rss.FeedItem;
import org.apache.camel.Exchange;
import org.apache.camel.Processor;
import org.apache.camel.ProducerTemplate;
import org.jboss.logging.Logger;
import com.rometools.rome.feed.synd.SyndEntry;
import com.rometools.rome.feed.synd.SyndFeed;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
public class RssFeedProcesor implements Processor {
private final Set<String> processedItems = ConcurrentHashMap.newKeySet();
private final static Logger log = Logger.getLogger(RssFeedProcesor.class);
@Override
public void process(Exchange exchange) {
Object body = exchange.getMessage().getBody();
if (!(body instanceof SyndFeed feed)) {
log.warnf(”Expected SyndFeed but got: %s”, body != null ? body.getClass().getName() : “null”);
exchange.getMessage().setBody(null);
return;
}
log.infof(”Processing feed: %s with %d entries”, feed.getTitle(), feed.getEntries().size());
int[] counts = { 0, 0 };
feed.getEntries().stream()
.filter(entry -> !processedItems.contains(createUniqueKey(entry)))
.forEach(entry -> {
processedItems.add(createUniqueKey(entry));
counts[0]++;
String author = Optional.ofNullable(entry.getAuthor()).orElse(”unknown”);
FeedItem item = new FeedItem(entry.getTitle(), entry.getLink(), author,
Optional.ofNullable(entry.getPublishedDate())
.map(date -> date.toInstant().atOffset(ZoneOffset.UTC))
.orElse(null));
try (ProducerTemplate template = exchange.getContext().createProducerTemplate()) {
template.sendBodyAndHeaders(”direct:processEntry”, item,
Map.of(”author”, author, “month”, extractMonth(entry)));
} catch (Exception e) {
log.error(”Error processing entry: {}”, entry, e);
}
});
counts[1] = feed.getEntries().size() - counts[0];
exchange.getMessage().setBody(null);
log.infof(”Feed processing complete: %d new items processed, %d items skipped”, counts[0], counts[1]);
}
private String createUniqueKey(SyndEntry entry) {
return entry.getTitle() + “|” + entry.getLink() + “|” +
(entry.getPublishedDate() != null ? entry.getPublishedDate().getTime() : “no-date”);
}
private String extractMonth(SyndEntry entry) {
String rslt = “unknown”;
if (entry.getPublishedDate() != null) {
OffsetDateTime publishedDate = entry.getPublishedDate().toInstant()
.atOffset(java.time.ZoneOffset.UTC);
rslt = publishedDate.format(DateTimeFormatter.ofPattern(”yyyy-MM”));
}
return rslt;
}
}RSS Feed Processing: Acts as an Apache Camel processor that handles RSS feed data (SyndFeed objects)
Duplicate Prevention: Maintains a thread-safe set of processed items to avoid processing the same RSS entries multiple times
Entry Filtering: Only processes new RSS entries that haven’t been seen before using a unique key based on title, link, and publication date
Data Transformation: Converts RSS entries (SyndEntry) into custom FeedItem objects with standardized fields (title, link, author, published date)
Message Routing: Forwards processed items to another Camel route (direct:processEntry) with additional metadata headers (author and month)
Error Handling: Catches and logs exceptions during entry processing without stopping the overall feed processing
Progress Tracking: Counts and logs how many new items were processed vs. skipped due to duplicates
Metadata Extraction: Extracts publication month in “yyyy-MM” format for categorization purposes
Application Scoped: Runs as a singleton bean in the Quarkus application context, maintaining state across multiple feed processing cycles
Optional REST endpoint to read latest items
This reads the JSONL file and returns the last N items. Helpful to verify the flow.
package org.acme;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import org.acme.rss.FeedItem;
import org.eclipse.microprofile.config.inject.ConfigProperty;
import com.fasterxml.jackson.databind.ObjectMapper;
import io.quarkus.logging.Log;
import jakarta.inject.Inject;
import jakarta.ws.rs.DefaultValue;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.QueryParam;
import jakarta.ws.rs.core.MediaType;
@jakarta.ws.rs.Path(”/feed”)
@Produces(MediaType.APPLICATION_JSON)
public class FeedResource {
@ConfigProperty(name = “app.out.filename”)
String outFilename;
@Inject
private ObjectMapper mapper;
private Path getOutFile() {
return Path.of(”target/out”, outFilename);
}
@GET
public List<FeedItem> latest(@QueryParam(”limit”) @DefaultValue(”5”) int limit) throws IOException {
Path outFile = getOutFile();
if (!Files.exists(outFile))
return List.of();
List<String> lines = Files.readAllLines(outFile);
if (lines.isEmpty()) {
return List.of();
}
List<FeedItem> items = new ArrayList<>();
for (String line : lines) {
if (line.trim().isEmpty())
continue;
try {
items.add(mapper.readValue(line.trim(), FeedItem.class));
} catch (Exception e) {
Log.error(”Failed to parse JSON: “ + line.substring(0, Math.min(100, line.length())));
}
}
// Get the last ‘limit’ items
int from = Math.max(0, items.size() - limit);
List<FeedItem> result = items.subList(from, items.size());
Collections.reverse(result); // newest first
return result;
}
}Run and verify
Start dev mode:
quarkus devWatch the logs. You should see entries polled and “Wrote item to sink.” A file appears at target/out/quarkus-feed.jsonl.
Verify with curl:
curl http://localhost:8080/feed
curl http://localhost:8080/feed?limit=10If no new data shows up for a while, the consumer likely deduped unchanged entries. That is expected.
Verify metrics
Check counters at the metrics endpoint:
curl http://localhost:8080/q/metrics | grep rss_items_totalYou’ll see something like:
rss_items_total{author=”Guillaume Smet (https://twitter.com/gsmet_)”,camelContext=”camel-1”,month=”2025-07”} 64.0
rss_items_total{author=”Guillaume Smet (https://twitter.com/gsmet_)”,camelContext=”camel-1”,month=”2025-08”} 48.0
rss_items_total{author=”Guillaume Smet (https://twitter.com/gsmet_)”,camelContext=”camel-1”,month=”2025-09”} 32.0
rss_items_total{author=”Luca Molteni (https://twitter.com/volothamp)”,camelContext=”camel-1”,month=”2025-06”} 8.0I have included a super small metrics.html page in the Github repository that displays some statistics directly from the health endpoint:
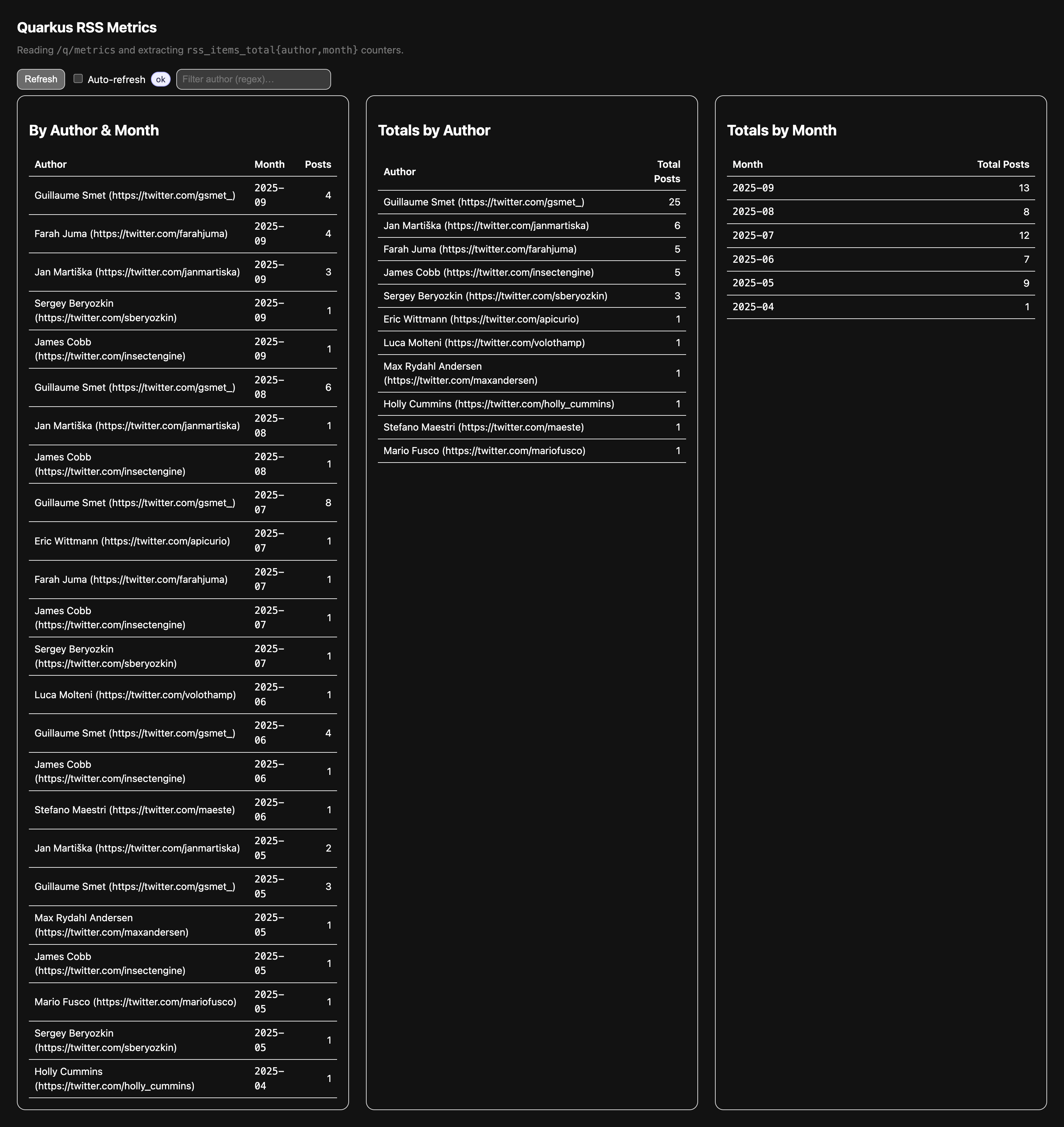
Congratulations to Guillaume Smet for publishing both the most posts on the Quarkus Blog and also the most posts in a single month :)
Production notes
Tune
consumer.delaybased on upstream rate and your SLOs. Start conservative.Use durable sinks for downstream processing. Replace
file:with Kafka, S3, JDBC, or Elasticsearch by switching the endpoint, not the business logic.For native images, verify the Camel Quarkus extensions you use are supported and run your tests against the native binary.
Wrapping Up
In this tutorial you built a complete RSS integration service with Quarkus and Camel. Starting from the Quarkus blog feed, you learned how to:
Use the Camel
rss:component to poll and split feed entries.Transform raw
SyndEntryobjects into a cleanFeedItemrecord.Log and persist entries as newline-delimited JSON files.
Expose a simple REST endpoint to read the processed items.
Extend the route with Camel’s Micrometer component to capture real-time statistics on authors and publications per month, exportable to Prometheus and Grafana.
Together these steps mirror the flow from Spring’s integration guide while showing how Quarkus and Camel make the same patterns lightweight, observable, and production-ready. You now have a working foundation you can evolve further: Swap the file sink for Kafka or a database, enrich feeds with extra processors, or build dashboards around the Micrometer metrics.
A small, fast Quarkus service, an expressive Camel DSL, and enterprise-grade observability. That’s a solid recipe for integration work done right.
Small, focused, and ready to extend.
Very nice example. As a Camel contributor, me too I'm looking often for realistic use cases for my workshops. The most difficult is to find the flow's starting point and, ln general, this is always an incoming XML or CSV set of files. But the idea of the RSS feed is great. and this is the first Camel example I'm seeing that uses it.
However, with your permission, I'd suggest that the Camel processor be refactored in a separate class or as a standalone Function, such that the Camel route becomes simpler, more focused on exchanges and more readable.