

Discover Hidden Themes in Your Writing with Quarkus and DeepLearning4j
A hands-on guide for Java developers to scrape, embed, and cluster Substack articles into meaningful categories with AI.


When you have written dozens of articles, it becomes very hard to organize them. You might start with simple tags like Quarkus or AI. But over time, the topics overlap. One article might be about Quarkus + AI + Security. Another may touch Architecture and Performance.
Tagging them all by hand is boring and often inconsistent. What if the computer could read your articles, find natural themes, and suggest categories for you?
That is exactly what we will build in this tutorial. We will create a Quarkus application that:
Scrapes my Substack articles
Turns them into vectors with DeepLearning4j (Doc2Vec)
Groups them into clusters with Smile’s k-means
Extracts keywords for each cluster with TF-IDF
Shows the results in a Qute web page with an interactive scatter plot
This is an end-to-end system that works without any manual labels. It discovers topics automatically.
Why Should I Even Read This Article?
Consistency: Machines don’t get tired or forget what label to use.
Scale: Works for hundreds of articles and can re-run monthly.
Insight: Shows hidden themes you might not notice yourself.
The same approach is useful in companies: you can cluster support tickets, bug reports, or logs to discover main themes.
Project setup
Java 21
Maven 3.9+
Quarkus CLI (optional)
Create the project:
quarkus create app com.example:substack-discovery:1.0.0 \
-x rest-jackson,rest-qute,qute
cd substack-discoveryThis gives us a clean Quarkus project with REST and CDI.
You can find all resources and the running example with my own Substack posts in my Github repository. Make sure to grab the full Qute page and the JavaScript pieces from there if you walk through this guide yourself.
Add dependencies
Open pom.xml and add the following:
<properties>
<dl4j.version>1.0.0-M2.1</dl4j.version>
<smile.version>4.4.1</smile.version>
</properties>
<dependencies>
<!-- DeepLearning4j for embeddings -->
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-nlp</artifactId>
<version>${dl4j.version}</version>
</dependency>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native-platform</artifactId>
<version>${dl4j.version}</version>
</dependency>
<!-- Smile for clustering and visualization -->
<dependency>
<groupId>com.github.haifengl</groupId>
<artifactId>smile-core</artifactId>
<version>${smile.version}</version>
</dependency>
<dependency>
<groupId>com.github.haifengl</groupId>
<artifactId>smile-plot</artifactId>
<version>${smile.version}</version>
</dependency>
<!-- HTML parsing -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.21.2</version>
</dependency>
</dependencies>Why these?
DL4J + ND4J: embeddings with Doc2Vec.
Smile: clustering (k-means) and t-SNE projection.
Jsoup: scraping Substack pages.
Qute: the web UI.
Scrape articles
We need to get plain text from the Substack URLs. Jsoup makes this easy.
package com.example.scrape;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Scraper {
public static String fetch(String url) throws Exception {
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0 Quarkus-Discovery")
.timeout(20000)
.get();
doc.select("script,style,noscript,header,footer,nav").remove();
return doc.body().text().replaceAll("\\s+"," ").trim();
}
}This strips scripts and menus so we only keep article text.
Turn articles into vectors (Doc2Vec)
We need fixed-size vectors that capture article meaning. Doc2Vec is a classic and efficient way to do this.
package com.example.embed;
import java.util.List;
import org.deeplearning4j.models.paragraphvectors.ParagraphVectors;
import org.deeplearning4j.text.sentenceiterator.CollectionSentenceIterator;
import org.deeplearning4j.text.tokenization.tokenizerfactory.DefaultTokenizerFactory;
import org.jboss.logging.Logger;
public class Embedder {
private static final Logger LOG = Logger.getLogger(Embedder.class);
public static ParagraphVectors train(List<String> docs) {
LOG.info("Starting ParagraphVectors training with " + docs.size() + " documents...");
var iterator = new CollectionSentenceIterator(docs);
var tok = new DefaultTokenizerFactory();
ParagraphVectors vec = new ParagraphVectors.Builder()
.iterate(iterator)
.tokenizerFactory(tok)
.layerSize(100) // 200 to 100 for faster training
.epochs(5) // 10 to 5 epochs
.minWordFrequency(1) // 2 to 1 for more words
.trainWordVectors(true)
.build();
LOG.info("Training ParagraphVectors model...");
vec.fit();
LOG.info("ParagraphVectors training completed!");
return vec;
}
}Cluster articles
We use Smile’s k-means to group vectors into clusters. Each cluster is a potential topic.
package com.example.cluster;
import smile.clustering.KMeans;
public class Clusterer {
public static KMeans cluster(double[][] features, int k) {
return KMeans.fit(features, k);
}
}Extract keywords with TF-IDF
Once we have clusters, we still need to make them human-readable. A cluster labeled just as “Cluster 0” isn’t useful. We need to know what kind of articles live in that group.
The classic approach is TF-IDF (Term Frequency–Inverse Document Frequency). It scores words based on two things:
How often a word appears in documents of this cluster (TF).
How rare that word is across all documents (IDF).
The higher the score, the more “signature” that word is for the cluster.
In our updated implementation, we also add strong filtering:
Stop words like and, the, with are ignored.
Java keywords and boilerplate terms like
public,void,class,import, and even common technical words likeconfigorbeanare filtered out. These don’t help us understand real content themes.We only keep words with at least three characters and some real semantic weight.
This ensures that the final keywords are meaningful to humans, not just technical noise. For example, instead of getting keywords like “class, import, void”, we’ll surface words like “ai, security, caching, langchain4j, observability”.
Here is the implementation:
package com.example.cluster;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.stream.Collectors;
import org.deeplearning4j.text.stopwords.StopWords;
public class TfIdfExtractor {
// Additional Java programming and technical qualifiers to filter out (minimal
// set)
private static final Set<String> JAVA_TECHNICAL_TERMS = Set.of(
// Most common Java keywords that don't add semantic value
"import", "public", "private", "static", "final", "class", "interface", "package", "void",
"null", "true", "false", "if", "else", "while", "for", "switch", "case", "break", "continue",
"try", "catch", "finally", "throw", "throws", "new", "this", "super", "return", "instanceof",
"do", "goto", "const", "default", "byte", "short", "int", "long", "float", "double", "char",
"boolean", "string", "stringbuilder", "stringbuffer",
// Common Java packages that don't add semantic value
"javax", "jakarta", "org", "com", "net", "io", "util", "lang", "awt", "swing", "sql",
"time", "nio", "security", "crypto", "text", "math", "beans", "rmi", "jdbc", "jpa",
"jax", "jaxb", "jaxrs", "jaxws", "jms", "jta", "jndi", "jca", "jce", "jdo",
// HTML/XML tags that don't add semantic value
"div", "span", "p", "a", "img", "ul", "ol", "li", "table", "tr", "td", "th", "form", "input",
"button", "select", "option", "textarea", "label", "fieldset", "legend", "h1", "h2", "h3",
"h4", "h5", "h6", "br", "hr", "meta", "link", "script", "style", "title", "head", "body",
// Very common technical terms that don't add semantic value
"value", "data", "result", "config", "settings", "options", "params", "args", "arg", "param",
"id", "name", "type", "key", "val", "obj", "item", "list", "array", "map", "set",
"collection", "iterator", "stream", "optional", "nullable", "nonnull");
public static List<String> topTerms(List<String> docs, int n) {
Map<String, Integer> df = new HashMap<>();
List<Map<String, Integer>> termFreqs = new ArrayList<>();
for (String doc : docs) {
String[] tokens = doc.toLowerCase().split("\\W+");
Map<String, Integer> tf = new HashMap<>();
for (String t : tokens) {
// Filter out short words, stop words, and Java technical terms
if (t.length() < 3 || StopWords.getStopWords().contains(t) || JAVA_TECHNICAL_TERMS.contains(t))
continue;
tf.put(t, tf.getOrDefault(t, 0) + 1);
}
termFreqs.add(tf);
for (String t : tf.keySet())
df.put(t, df.getOrDefault(t, 0) + 1);
}
int totalDocs = docs.size();
Map<String, Double> scores = new HashMap<>();
for (Map<String, Integer> tf : termFreqs) {
for (Map.Entry<String, Integer> e : tf.entrySet()) {
String term = e.getKey();
double idf = Math.log((1.0 + totalDocs) / (1.0 + df.get(term))) + 1.0;
double tfidf = e.getValue() * idf;
scores.put(term, scores.getOrDefault(term, 0.0) + tfidf);
}
}
return scores.entrySet().stream()
.sorted(Map.Entry.<String, Double>comparingByValue().reversed())
.limit(n)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
}
}Understanding ParagraphVectors Configuration
Once we clean up our text with TF-IDF, we still rely on ParagraphVectors (Doc2Vec) to produce the actual embeddings that power clustering and visualization. This model has a few important hyperparameters. Two of the most critical are layer size and epochs.
Layer Size (100)
The dimensionality of the vector embeddings or how many numbers represent each paragraph or article.
Each paragraph is transformed into a vector of 100 numbers.
These 100 dimensions capture different semantic aspects of the text.
You can think of it as describing an article with 100 different “characteristics.”
Trade-offs:
Smaller (50–100): trains faster, uses less memory, but might miss subtle meanings.
Larger (200–300): captures more complexity, but is slower and heavier in memory.
Our choice (100): a balanced sweet spot for most use cases.
// Example: one paragraph → 100 numbers
// [0.23, -0.45, 0.12, 0.89, ..., -0.34]Epochs (5)
How many complete passes the model makes through the training dataset.
With
epochs(5), the model reads all articles five times.Each pass refines the embeddings, similar to studying the same material multiple times.
Trade-offs:
Too few (1–3): model underfits, doesn’t capture enough patterns.
Too many (20+): model overfits, memorizing training data instead of generalizing.
Our choice (5): a safe starting point that balances quality and efficiency.
// Epoch 1: Initial embeddings
// Epoch 2: Refine based on context
// Epoch 3: Stronger patterns
// Epoch 4: Further polish
// Epoch 5: Final embeddings readyHow They Work Together
The combination of 100-dimensional embeddings and 5 training epochs gives us vectors that are:
Large enough to capture semantic themes.
Trained long enough to generalize well.
Still efficient in both time and memory.
In practice, this means:
// Each article → 100-number vector
// Training time: ~5 full passes through the data
// Memory usage: Moderate
// Result quality: Good for clustering and visualizationWhen to Adjust
Increase layer size if the text is very diverse, you need subtle distinctions, and you have plenty of training data.
Increase epochs if the model is still improving after the chosen number, or if you notice underfitting.
Our settings layer size 100 and epochs 5 are sensible defaults. They deliver good quality document embeddings without making training unnecessarily slow or resource-intensive.
Visualize with t-SNE
When we create embeddings with Doc2Vec, each article becomes a vector of 200 numbers. These vectors live in a 200-dimensional space. That is impossible for humans to imagine.
Clustering works fine in high dimensions, but to see the groups, we need to reduce the data to 2D. This is where t-SNE (t-Distributed Stochastic Neighbor Embedding) comes in.
t-SNE:
It takes the high-dimensional vectors and projects them into two dimensions.
It tries to preserve local neighborhoods, meaning that if two articles are close in the original 200-dim space, they will also be close in the 2D scatter plot.
The result is a map where clusters of related articles form visible “islands”.
Why not just use PCA?
PCA (Principal Component Analysis) is faster but linear. It often misses subtle non-linear structures. t-SNE is slower but much better at showing meaningful clusters in text embeddings.
With Smile, the call is simple. We’ll use this in the Page Resource later!
import smile.manifold.TSNE;
// features is double[][] from Doc2Vec
double[][] coords = TSNE.of(features, 2);featuresis the array of all your article vectors.2means we want two dimensions: x and y.The result
coordshas the same length as your article list. Each entry is[x, y].
We store these (x, y) coordinates with each article and send them to the Qute template. In the browser we draw them as dots in a scatter plot. Dots with the same cluster color group together, and keywords tell us what the cluster means.
Tight clouds: articles strongly related (for example, all “LangChain4j + Quarkus” tutorials).
Overlap: articles that touch multiple themes may sit between clusters.
Outliers: single dots far away often represent unique topics.
This way, clustering becomes not just numbers and keywords but something you can see and reason about.
Scraping and Model Generation at Startup
We do all the heavy work once, at application startup. Quarkus provides the StartupEvent, which lets you run initialization logic as soon as the app boots. In our StartupService, we do the scraping, model training, clustering, and keyword extraction in this startup phase. The results are stored in memory (cachedClusters) and reused by the REST endpoint.
We also added a simple caching layer:
On startup, the service checks if a serialized cache file exists in
target/clusters_cache.ser.If the cache is younger than 24 hours, it loads the clusters directly, skipping scraping and model generation.
If the cache is missing or too old, the system processes everything again and then saves fresh results to disk.
When the
/discoverendpoint runs, it simply reads fromcachedClusters. It doesn’t care if the data came from the cache or a fresh run.
This gives us three big wins:
Faster startup after the first run. No need to recompute everything every time.
Less load on Substack, because scraping only happens once a day.
Automatic refresh: data stays reasonably up-to-date without manual intervention.
This basically is like a smart data pipeline: it crunches hard once at startup (or once a day when the cache expires), and serves lightweight results instantly after that.
package com.example;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CompletableFuture;
import org.deeplearning4j.models.paragraphvectors.ParagraphVectors;
import org.jboss.logging.Logger;
import org.nd4j.linalg.api.ndarray.INDArray;
import com.example.cluster.Clusterer;
import com.example.cluster.TfIdfExtractor;
import com.example.embed.Embedder;
import com.example.scrape.Scraper;
import com.example.view.ClusterView;
import io.quarkus.runtime.StartupEvent;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.event.Observes;
import smile.clustering.KMeans;
import smile.manifold.TSNE;
@ApplicationScoped
public class StartupService {
private static final Logger LOG = Logger.getLogger(StartupService.class);
private static final String CACHE_FILE = "target/clusters_cache.ser";
private List<ClusterView> cachedClusters = new ArrayList<>();
private boolean isProcessing = false;
private int processedCount = 0;
private int totalCount = 0;
void onStart(@Observes StartupEvent ev) {
LOG.info("Application starting up - checking for cached data...");
if (loadCachedData()) {
LOG.info("Loaded cached clusters data. Found " + cachedClusters.size() + " clusters.");
} else {
LOG.info("No cached data found - beginning data processing...");
processDataAsync();
}
}
private void processDataAsync() {
CompletableFuture.runAsync(() -> {
try {
isProcessing = true;
processData();
} catch (Exception e) {
LOG.error("Error during data processing", e);
} finally {
isProcessing = false;
}
});
}
private void processData() throws Exception {
LOG.info("Loading URLs from data file...");
List<String> urls = Files.readAllLines(Paths.get("src/main/resources/data/data.txt"));
totalCount = urls.size();
LOG.info("Found " + totalCount + " URLs to process");
// scrape
LOG.info("Starting web scraping...");
List<String> texts = new ArrayList<>();
for (int i = 0; i < urls.size(); i++) {
String url = urls.get(i);
LOG.info("Scraping " + (i + 1) + "/" + totalCount + ": " + url);
texts.add(Scraper.fetch(url));
processedCount = i + 1;
}
LOG.info("Scraping completed. Starting embedding...");
// embed
ParagraphVectors vec = Embedder.train(texts);
LOG.info("Generating feature vectors for " + texts.size() + " articles...");
// vectors
double[][] features = new double[texts.size()][];
for (int i = 0; i < texts.size(); i++) {
if (i % 10 == 0) {
LOG.info("Generating vector " + (i + 1) + "/" + texts.size() + " ("
+ String.format("%.1f", (i * 100.0 / texts.size())) + "%)");
}
INDArray v = vec.inferVector(texts.get(i));
features[i] = v.toDoubleVector();
}
LOG.info("Feature vector generation completed!");
LOG.info("Clustering data...");
// cluster
int k = 6;
KMeans km = Clusterer.cluster(features, k);
LOG.info("Computing t-SNE coordinates...");
// tsne
TSNE tsne = new TSNE(features, 2);
double[][] coords = tsne.coordinates;
LOG.info("Building cluster views...");
// build view
List<ClusterView> clusters = new ArrayList<>();
for (int c = 0; c < k; c++) {
List<String> clusterDocs = new ArrayList<>();
List<String> clusterUrls = new ArrayList<>();
List<double[]> clusterCoords = new ArrayList<>();
for (int i = 0; i < urls.size(); i++) {
if (km.y[i] == c) {
clusterDocs.add(texts.get(i));
clusterUrls.add(urls.get(i));
clusterCoords.add(coords[i]);
}
}
if (!clusterDocs.isEmpty()) {
ClusterView cv = new ClusterView();
cv.clusterId = c;
cv.keywords = TfIdfExtractor.topTerms(clusterDocs, 8);
LOG.info("Cluster " + c + " keywords: " + cv.keywords);
LOG.info("Cluster " + c + " keywords size: " + cv.keywords.size());
LOG.info("Cluster " + c + " first keyword: " + (cv.keywords.isEmpty() ? "EMPTY" : cv.keywords.get(0)));
cv.articles = new ArrayList<>();
for (int i = 0; i < clusterUrls.size(); i++) {
ClusterView.ArticleView av = new ClusterView.ArticleView();
av.url = clusterUrls.get(i);
av.x = clusterCoords.get(i)[0];
av.y = clusterCoords.get(i)[1];
cv.articles.add(av);
}
clusters.add(cv);
}
}
cachedClusters = clusters;
LOG.info("Data processing completed! Generated " + clusters.size() + " clusters");
// Save to cache
saveCachedData();
}
public List<ClusterView> getClusters() {
return cachedClusters;
}
public boolean isProcessing() {
return isProcessing;
}
public int getProcessedCount() {
return processedCount;
}
public int getTotalCount() {
return totalCount;
}
private boolean loadCachedData() {
try {
if (Files.exists(Paths.get(CACHE_FILE))) {
// Check if cache is recent (less than 24 hours old)
long cacheAge = System.currentTimeMillis()
- Files.getLastModifiedTime(Paths.get(CACHE_FILE)).toMillis();
if (cacheAge < 24 * 60 * 60 * 1000) { // 24 hours
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(CACHE_FILE))) {
@SuppressWarnings("unchecked")
List<ClusterView> loaded = (List<ClusterView>) ois.readObject();
if (loaded != null && !loaded.isEmpty()) {
cachedClusters = loaded;
LOG.info("Loaded cached data (age: " + (cacheAge / (60 * 60 * 1000)) + " hours)");
return true;
}
}
} else {
LOG.info("Cache is too old (" + (cacheAge / (60 * 60 * 1000)) + " hours), will reprocess");
}
}
} catch (IOException | ClassNotFoundException e) {
LOG.warn("Failed to load cached data: " + e.getMessage());
}
return false;
}
private void saveCachedData() {
try {
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(CACHE_FILE))) {
oos.writeObject(cachedClusters);
LOG.info("Cached clusters data saved to " + CACHE_FILE);
}
} catch (IOException e) {
LOG.error("Failed to save cached data: " + e.getMessage());
}
}
}The service also tracks progress (processedCount and totalCount) so you could show a loading screen in the UI while it’s working. When finished, the cachedClusters object holds everything the frontend or API needs.
Checking Progress with a Status Endpoint
When the application starts, scraping and model generation can take a while. Especially if you have many articles. It’s helpful to know whether the system is still working or already done. For that, we add a simple status resource.
The StatusResource exposes a /status endpoint that reports:
Whether processing is still running.
How many articles have already been processed.
The total number of articles.
A calculated progress percentage.
Here’s the implementation:
@Path("/status")
public class StatusResource {
@Inject
StartupService startupService;
@GET
@Produces(MediaType.APPLICATION_JSON)
public StatusResponse getStatus() {
return new StatusResponse(
startupService.isProcessing(),
startupService.getProcessedCount(),
startupService.getTotalCount()
);
}
public static class StatusResponse {
public boolean processing;
public int processed;
public int total;
public double progress;
public StatusResponse(boolean processing, int processed, int total) {
this.processing = processing;
this.processed = processed;
this.total = total;
this.progress = total > 0 ? (double) processed / total * 100 : 0;
}
}
}
If you call it with curl http://localhost:8080/status, you might see:
{
"processing": true,
"processed": 12,
"total": 50,
"progress": 24.0
}
Exposing Clusters as JSON
Before we build out a Qute UI, let’s just expose the data in a machine-readable format. This makes it easier to debug and also to integrate with another service, run further analysis, or build a frontend in React or Vue.
That’s what the ClustersResource does. It exposes a /clusters endpoint that simply returns the list of clusters in JSON. Each cluster contains its ID, the extracted keywords, and the articles with their 2D coordinates for visualization.
@Path("/clusters")
public class ClustersResource {
@Inject
StartupService startupService;
@GET
@Produces(MediaType.APPLICATION_JSON)
public List<ClusterView> getClusters() {
return startupService.getClusters();
}
}Because all the heavy work (scraping, embeddings, clustering, keyword extraction, t-SNE projection) is already done inside StartupService at application startup, this endpoint is very lightweight. It just reads the cached results from memory and serializes them to JSON.
You can test it with:
curl http://localhost:8080/clusters | jqThe response looks like this:
[
{
"clusterId": 0,
"keywords": ["quarkus","rest","api","panache","caching"],
"articles": [
{ "url": "https://example.com/quarkus-getting-started", "x": 12.3, "y": -4.5 },
{ "url": "https://example.com/quarkus-caching", "x": 11.8, "y": -5.1 }
]
},
{
"clusterId": 1,
"keywords": ["ai","langchain4j","embeddings","prompt"],
"articles": [
{ "url": "https://example.com/ai-langchain4j", "x": -3.2, "y": 7.9 }
]
}
]
This makes your clustering pipeline reusable: you can show it in Qute for humans or consume it as JSON for further automation.
Qute view model
Let’s define a simple view model.
package com.example.view;
import java.util.List;
public class ClusterView {
public int clusterId;
public List<String> keywords;
public List<ArticleView> articles;
public static class ArticleView {
public String url;
public double x;
public double y;
}
}Discover page resource
And now we need to render the page and we do this with Qute’s REST integration directly from a REST endpoint.
package com.example.api;
import java.util.List;
import com.example.StartupService;
import com.example.view.ClusterView;
import io.quarkus.qute.CheckedTemplate;
import io.quarkus.qute.TemplateInstance;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
@Path("/discover")
public class DiscoverPage {
@Inject
StartupService startupService;
@CheckedTemplate
public static class Templates {
public static native TemplateInstance page(List<ClusterView> clusters, int totalArticles, int totalKeywords);
}
@GET
@Produces(MediaType.TEXT_HTML)
public TemplateInstance render() {
List<ClusterView> clusters = startupService.getClusters();
// Calculate totals
int totalArticles = clusters.stream().mapToInt(c -> c.articles.size()).sum();
int totalKeywords = clusters.stream().mapToInt(c -> c.keywords.size()).sum();
return Templates.page(clusters, totalArticles, totalKeywords);
}
}Injects the
StartupService.Defines a checked Qute template (
Templates.page) to ensure type-safe binding between Java and HTML.On every
GET /discoverrequest, it retrieves the current list ofClusterViewobjects from the service and passes them into the Qute template.Produces the response as
text/html, so the user immediately sees the web page with clusters, keywords, and scatter plot instead of JSON.
Qute template
Create src/main/resources/templates/DiscoverPage/page.qute.html:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Discovered Topics</title>
<style> <!-- omitted for brevity --> </style>
</head>
<body>
<div class="container">
<div class="header">
<h1>Substack Discovery</h1>
<p>AI-powered clustering of The Main Thread articles</p>
</div>
<div class="stats">
<div class="stat">
<div class="stat-number" id="cluster-count">{clusters.size}</div>
<div class="stat-label">Clusters</div>
</div>
<div class="stat">
<div class="stat-number" id="article-count">{totalArticles}</div>
<div class="stat-label">Articles</div>
</div>
<div class="stat">
<div class="stat-number" id="keyword-count">{totalKeywords}</div>
<div class="stat-label">Keywords</div>
</div>
</div>
<div class="canvas-container">
<canvas id="plot" width="800" height="600"></canvas>
</div>
<div class="clusters" id="clusters">
{#for c in clusters}
<div class="cluster">
<div class="cluster-header">
<div class="cluster-id">Cluster {c.clusterId}</div>
<div class="keywords">
{#for keyword in c.keywords}
<span class="keyword">{keyword}</span>
{/for}
</div>
</div>
<div class="articles">
{#for a in c.articles}
<div class="article">
<a href="{a.url}" target="_blank">{a.url}</a>
</div>
{/for}
</div>
</div>
{/for}
</div>
</div>
<script src="/application.js"></script>
</body>
</html>
The application.js file is a static resource and served from /resources/META-INF/resources. It handles everything on the browser side. Its job is to connect to the Quarkus backend, fetch the cluster data, and then render it as an interactive scatter plot.
At a high level, it does two things:
Data loading
Calls
/clustersto fetch the JSON produced by your Quarkus backend.If the request works, it updates the UI and hides the loading spinner.
If there’s an error, it shows an error message.
Visualization
Uses an HTML5
<canvas>element to draw a scatter plot of the clusters.Each cluster gets a different color.
Points represent articles, positioned with the t-SNE coordinates.
A legend shows which color belongs to which cluster and how many articles it contains.
The script is initialized with a DOMContentLoaded listener, so everything runs automatically when the page is loaded.
Run and verify
Create
data/data.txtwith your Substack links. I’ve included an example for my posts in /resources/data/data.txt. You can simply access your sitemap and parse the links that start with /q/ and put that into a file if you want to run it on your own Substack. Similar approach for other websites.Start the app:
./mvnw quarkus:devWait for the model generation to finish (watch the logs!)
INFO Time spent on training: 26978 ms
INFO ParagraphVectors training completed!
INFO Generating feature vectors for 219 articles...
INFO Generating vector 1/219 (0.0%)
INFO Generating vector 11/219 (4.6%)
INFO Generating vector 21/219 (9.1%)
INFO Generating vector 31/219 (13.7%)
...
INFO Data processing completed! Generated 6 clustersOpen in browser: http://localhost:8080/discover
You’ll see colored dots (each cluster) and below them the keywords plus article links.
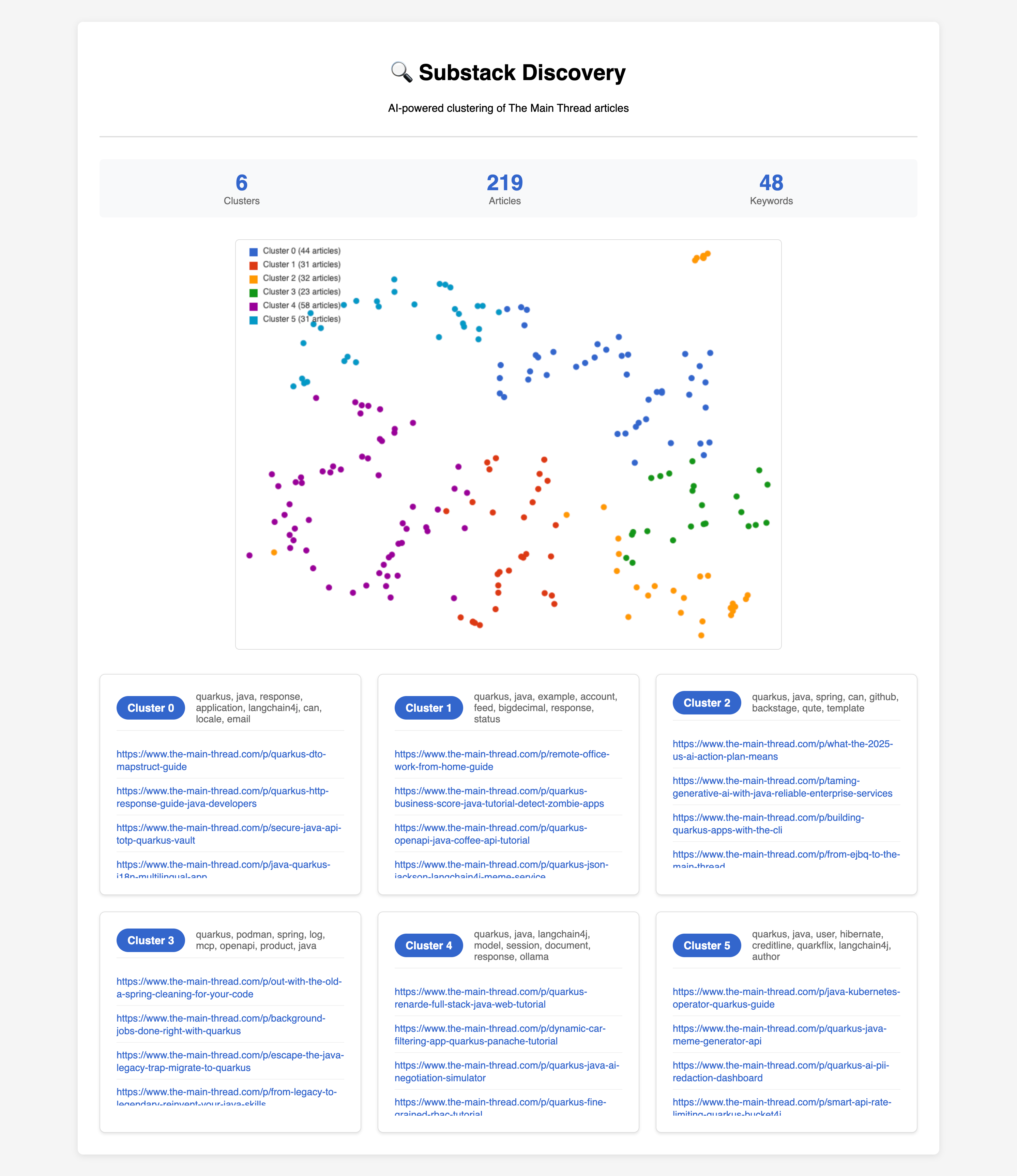
Next steps
Tune cluster number: Adjust
kfor better grouping.Re-run regularly: Refresh clusters monthly to reflect new posts.
Multi-label variation: Instead of one cluster per article, assign to multiple clusters if it sits close to more than one centroid.
Here’s a polished drop-in section for your article, explaining performance tuning for the demo in a clear, guided style:
Performance Optimization with ND4J
When you run deep learning models, performance depends heavily on how many CPU threads ND4J (the numerical engine behind Deeplearning4j) can use. By default, ND4J guesses based on your hardware, but for larger workloads like scraping, embedding, and clustering dozens of articles, it is worth tuning.
Threading Configuration
We want ND4J to fully use all available CPU cores. On a 16-core machine, that means running the heavy linear algebra operations in parallel.
For a simple, static setup, add nd4j.properties to your src/main/resources directory:
org.nd4j.linalg.cpu.nativecpu.threads=16
org.nd4j.parallel.threads=16
org.nd4j.linalg.api.ops.executioner.num_threads=16This way the configuration is automatically applied whenever Quarkus starts.
Finding the Sweet Spot
If you have 16 logical cores, start with
OMP_NUM_THREADS=16.Sometimes fewer threads (e.g., 8 for 8 physical cores) give better throughput because of hyper-threading.
Monitor CPU utilization while clustering to find the optimal value.
Always restart the application after changing threading settings so ND4J picks them up.
Without tuning, your application may silently use just a fraction of your CPU. With proper configuration, the ParagraphVectors training and clustering steps run significantly faster, making the startup experience smooth even with dozens or hundreds of articles.
Closing thought
With less than 300 lines of Java code, we built a system that scrapes, analyzes, clusters, labels, and visualizes your entire Substack archive. No manual tagging needed. You now have a map of your content that evolves with you.