

Build Local Image Search with Quarkus, ONNX, and pgvector (No Cloud Required)
A hands-on guide for Java developers to run fast, offline visual similarity search using ONNX Runtime, LangChain4j, and PostgreSQL.


Most AI conversations in the Java world still orbit around LLMs. They dominate the headlines, the conference talks, and the collective imagination. But the moment you step away from text, an entirely different class of problems appears—problems that traditional enterprise systems actually deal with every day. Think product catalogs, digital asset libraries, insurance damage photos, spare parts matching, medical imaging, quality control, document layout analysis, the list keeps growing.
These are high-value, high-impact use cases. And they have nothing to do with generating text.
They’re about understanding pixels.
If you want to build visual similarity search like “show me products that look like this,” “find matching components,” “locate images with the same layout”, most teams reach for cloud APIs by default. It’s the path of least resistance, but it comes with familiar drawbacks:
Unpredictable latency (100–300 ms per request)
Costs that scale linearly with every query
No offline or edge deployment story
Compliance risks around data residency
Lock-in that’s hard to reverse
Tooling that assumes your service is written in Python, not Java
That last point matters more than people admit. Python is fantastic for data science workflows, for model experimentation, and yes, for exporting neural networks to ONNX. But it’s not how you build durable, scalable, maintainable enterprise applications. That work happens in Java, on platforms like Quarkus.
This tutorial shows how to bridge those two worlds cleanly:
use Python once to export the CLIP vision model to ONNX (a job data science teams already know how to do), then run everything else, preprocessing, inference, vector storage, and similarity search, entirely inside your Java microservice.
The result is a fast, local, enterprise-grade image search engine that runs natively in Quarkus with zero cloud dependency and zero Python runtime anywhere near production.
Why ONNX Runtime Solves This
ONNX Runtime gives Java developers:
Local, offline inference
Fast vector generation (CLIP 512D vectors in ~20–50 ms)
GPU optionality
Enterprise compliance with JVM-based deployment models
Why LangChain4j Completes the Stack
Quarkus’ LangChain4j extension provides:
A clean EmbeddingModel abstraction that we can abuse here
A pgvector store with automatic schema creation
Search APIs for vector similarity
Seamless Quarkus integration
What You’ll Build
A fully local product image similarity service:
Users upload product images.
The app extracts embeddings with ONNX CLIP.
Embeddings are stored in PostgreSQL with pgvector.
A REST endpoint finds visually similar items in <100 ms.
No external APIs. No cloud cost.
Perfect for enterprise-grade Java systems where images live inside secure environments.
Architecture Overview
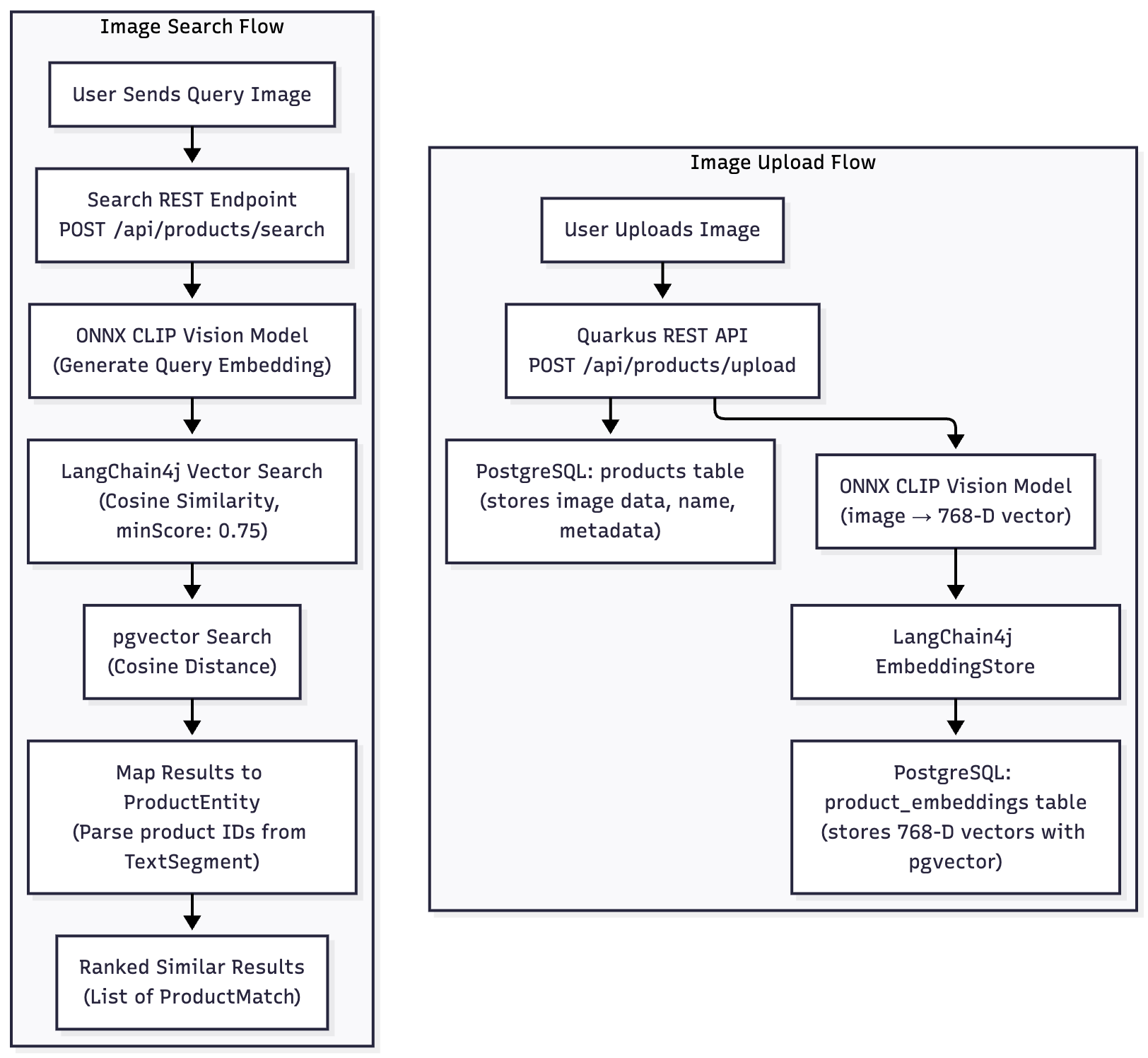
Key Components
ONNX Runtime Java – Runs CLIP transform inside Quarkus
Custom EmbeddingModel implementation – Wraps ONNX into LangChain4j Embedding
pgvector – Efficient vector similarity via cosine distance
Quarkus REST – API for upload and search
All JVM-native. (Just some very little!) Python. No cloud dependencies.
Prerequisites
java -version # Java 21+
quarkus version # Quarkus CLI
docker --version # For PostgreSQL pgvector
python3 :-/ # to create a ONNX model we can useFiles Required
Sample product images (you can add a /samples folder)
Project Setup
You can follow along or just download or clone the project form my Github repository.
Create Quarkus Project
quarkus create app com.example:image-search \
--extension='rest-jackson,jdbc-postgresql,hibernate-orm-panache,langchain4j-pgvector' \
--no-code
cd image-searchAdd Dependencies
onnxruntime is the core Java library for loading and running ONNX models; it provides the API (OrtEnvironment, OrtSession, OnnxTensor) used to execute your CLIP vision model and generate embeddings.
<!-- pom.xml -->
<dependency>
<groupId>com.microsoft.onnxruntime</groupId>
<artifactId>onnxruntime</artifactId>
<version>1.17.1</version>
</dependency>Prepare a non-quantized FP32 ONNX model
If you download a ready made quantized CLIP model (INT8), ONNX Runtime for Java cannot load it.
The reason is simple: the Java binding only ships with the standard FP32 execution engine, and quantized models depend on extra operators such as ConvInteger. These operators are implemented only in platform-specific execution providers (QNN, NNAPI, CoreML, CUDA), none of which are included in the default Java package.
Using the full-precision FP32 CLIP model avoids this completely.
It’s larger and slightly slower, but:
FP32 uses standard convolution ops
These ops are fully supported in all ONNX Runtime builds
No extra execution providers or native libraries required
Everything works out-of-the-box inside Quarkus
For JVM applications, FP32 is the safest and most portable choice. So, let’s bite the bullet and create a FP32 version quickly.
# Create a virtual python environment
python3 -m venv venv
# Activate it
source venv/bin/activate # On macOS/Linux
# or on Windows: venv\Scripts\activate
# Install packages
pip install torch transformers onnx pillowAnd now create convert.py
import torch
from transformers import CLIPModel, CLIPProcessor
import onnx
# Download and load the model
model = CLIPModel.from_pretrained(”openai/clip-vit-base-patch32”)
processor = CLIPProcessor.from_pretrained(”openai/clip-vit-base-patch32”)
model.eval()
# Export the vision encoder (for image embeddings)
dummy_input = torch.randn(1, 3, 224, 224)
torch.onnx.export(
model.vision_model,
dummy_input,
“clip_vision_fp32.onnx”,
input_names=[’pixel_values’],
output_names=[’last_hidden_state’, ‘pooler_output’],
dynamic_axes={
‘pixel_values’: {0: ‘batch_size’},
‘last_hidden_state’: {0: ‘batch_size’},
‘pooler_output’: {0: ‘batch_size’}
},
opset_version=14,
do_constant_folding=True
)
print(”✓ Vision model exported to clip_vision_fp32.onnx”)
# Verify the model
onnx_model = onnx.load(”clip_vision_fp32.onnx”)
onnx.checker.check_model(onnx_model)
print(”✓ Model verified successfully”)And run it:
python3 convert.pyMove the resulting clip_vision_fp32.onnx to src/main/resources/models/
Implement ONNX CLIP Embedding Model
OnnxClipEmbeddingModel is an @ApplicationScoped bean that plugs the ONNX CLIP vision model into LangChain4j’s EmbeddingModel API. It loads the model at startup, takes raw image bytes, preprocesses them with ImagePreprocessor, and runs inference through ONNX Runtime to produce a 768-dimensional embedding. It also handles different tensor shapes returned by various CLIP model builds, applies L2 normalization, and wraps the result as a LangChain4j Embedding for vector search. The text-based embed() method is intentionally unsupported because this implementation is strictly for images.
Create: src/main/java/com/example/embeddings/OnnxClipEmbeddingModel.java
package com.example.embeddings;
import java.awt.image.BufferedImage;
import java.io.ByteArrayInputStream;
import java.nio.FloatBuffer;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import javax.imageio.ImageIO;
import org.eclipse.microprofile.config.inject.ConfigProperty;
import ai.onnxruntime.OnnxTensor;
import ai.onnxruntime.OrtEnvironment;
import ai.onnxruntime.OrtException;
import ai.onnxruntime.OrtSession;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.output.Response;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
public class OnnxClipEmbeddingModel implements EmbeddingModel {
private final OrtEnvironment env;
private final OrtSession session;
private final ImagePreprocessor preprocess;
public OnnxClipEmbeddingModel(
@ConfigProperty(name = “clip.model.path”) String modelPath) throws OrtException {
this.env = OrtEnvironment.getEnvironment();
this.session = env.createSession(modelPath, new OrtSession.SessionOptions());
this.preprocess = new ImagePreprocessor(224, 224);
}
@Override
public Response<Embedding> embed(TextSegment textSegment) {
throw new UnsupportedOperationException(”Use embed(byte[]) for images”);
}
@Override
public Response<List<Embedding>> embedAll(List<TextSegment> textSegments) {
List<Embedding> embeddings = textSegments.stream()
.map(segment -> embed(segment).content())
.collect(Collectors.toList());
return Response.from(embeddings);
}
public Response<Embedding> embed(byte[] imageBytes) {
try {
BufferedImage img = ImageIO.read(new ByteArrayInputStream(imageBytes));
float[] pixels = preprocess.process(img);
long[] shape = { 1, 3, 224, 224 }; // NCHW
OnnxTensor input = OnnxTensor.createTensor(env, FloatBuffer.wrap(pixels), shape);
OrtSession.Result result = session.run(Map.of(”pixel_values”, input));
Object outputValue = result.get(0).getValue();
float[] vector;
// Handle different output shapes
if (outputValue instanceof float[][][]) {
// 3D array: [batch, 1, features] or similar
float[][][] output3d = (float[][][]) outputValue;
vector = output3d[0][0];
} else if (outputValue instanceof float[][]) {
// 2D array: [batch, features]
float[][] output2d = (float[][]) outputValue;
vector = output2d[0];
} else if (outputValue instanceof float[]) {
// 1D array: [features]
vector = (float[]) outputValue;
} else {
throw new RuntimeException(”Unexpected output type: “ + outputValue.getClass());
}
normalize(vector);
return Response.from(Embedding.from(vector));
} catch (Exception e) {
throw new RuntimeException(”Embedding failed”, e);
}
}
private void normalize(float[] v) {
float sum = 0;
for (float f : v)
sum += f * f;
float norm = (float) Math.sqrt(sum);
for (int i = 0; i < v.length; i++)
v[i] /= norm;
}
}Image Preprocessing
ImagePreprocessor exists because the CLIP vision model has strict input requirements that raw images don’t meet. It resizes every image to 224×224, converts RGB values from 0–255 into normalized floats using CLIP’s mean and standard deviation, and outputs the data in NCHW format (all R values first, then G, then B). This is the exact layout the ONNX CLIP model expects. Without this step, the model would receive improperly sized or incorrectly normalized tensors and produce useless embeddings. Bilinear interpolation keeps the resized images visually stable so the embedding remains meaningful.
Create: src/main/java/com/example/embeddings/ImagePreprocessor.java
package com.example.embeddings;
import java.awt.Graphics2D;
import java.awt.RenderingHints;
import java.awt.image.BufferedImage;
public class ImagePreprocessor {
private final int width;
private final int height;
// CLIP normalization
private static final float[] MEAN = { 0.48145466f, 0.4578275f, 0.40821073f };
private static final float[] STD = { 0.26862954f, 0.26130258f, 0.27577711f };
public ImagePreprocessor(int width, int height) {
this.width = width;
this.height = height;
}
public float[] process(BufferedImage image) {
BufferedImage resized = resize(image);
float[] out = new float[3 * width * height];
for (int y = 0; y < height; y++) {
for (int x = 0; x < width; x++) {
int rgb = resized.getRGB(x, y);
int r = (rgb >> 16) & 0xFF;
int g = (rgb >> 8) & 0xFF;
int b = rgb & 0xFF;
int idx = y * width + x;
out[idx] = (r / 255f - MEAN[0]) / STD[0];
out[idx + width * height] = (g / 255f - MEAN[1]) / STD[1];
out[idx + 2 * width * height] = (b / 255f - MEAN[2]) / STD[2];
}
}
return out;
}
private BufferedImage resize(BufferedImage original) {
BufferedImage out = new BufferedImage(width, height, BufferedImage.TYPE_INT_RGB);
Graphics2D g = out.createGraphics();
g.setRenderingHint(RenderingHints.KEY_INTERPOLATION, RenderingHints.VALUE_INTERPOLATION_BILINEAR);
g.drawImage(original, 0, 0, width, height, null);
g.dispose();
return out;
}
}LangChain4j pgvector Configuration
In the application.properties we set up the pgvector embedding store and the CLIP model. The pgvector settings create a product_embeddings table for 768-dimensional vectors (matching the CLIP model output) and enable automatic table creation. The CLIP model path points to the ONNX vision model file (clip_vision_fp32.onnx) used to generate embeddings. The dev profile setting enables HQL queries in the Hibernate ORM Dev UI for development debugging.
Change: src/main/resources/application.properties
# Vector store
quarkus.langchain4j.pgvector.table=product_embeddings
quarkus.langchain4j.pgvector.dimension=768
quarkus.langchain4j.pgvector.create-table=true
# CLIP model
# clip.model.path=src/main/resources/models/model_int8.onnx
clip.model.path=src/main/resources/models/clip_vision_fp32.onnx
%dev.quarkus.hibernate-orm.dev-ui.allow-hql=trueService Layer
ProductImageService is the core application service that ties embedding generation and vector search together. The addProduct method creates a new ProductEntity, stores the raw image, generates a CLIP embedding, and writes that vector to the pgvector-backed EmbeddingStore using a TextSegment that carries the product ID and metadata. The findSimilar method takes a query image, generates its embedding, performs a cosine-similarity search with a minimum score of 0.75, and then resolves the returned segments back to real ProductEntity records. It finally turns those matches into ProductMatch objects with their similarity scores. This service is the link between the ONNX CLIP model, the pgvector store, and the product data in PostgreSQL.
Create: src/main/java/com/example/embeddings/ProductImageService.java
package com.example.embeddings;
import java.util.List;
import java.util.Map;
import dev.langchain4j.data.document.Metadata;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.store.embedding.EmbeddingSearchRequest;
import dev.langchain4j.store.embedding.EmbeddingStore;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import jakarta.transaction.Transactional;
@ApplicationScoped
public class ProductImageService {
@Inject
OnnxClipEmbeddingModel clipModel;
@Inject
EmbeddingStore<TextSegment> vectorStore;
@Transactional
public ProductEntity addProduct(String name, byte[] imageBytes) {
ProductEntity p = new ProductEntity();
p.name = name;
p.imageData = imageBytes;
p.persist();
var response = clipModel.embed(imageBytes);
Embedding embedding = response.content();
TextSegment segment = TextSegment.from(
“product:” + p.id,
Metadata.from(Map.of(”name”, name)));
vectorStore.add(embedding, segment);
return p;
}
public List<ProductMatch> findSimilar(byte[] query, int limit) {
var response = clipModel.embed(query);
EmbeddingSearchRequest req = EmbeddingSearchRequest.builder()
.queryEmbedding(response.content())
.maxResults(limit)
.minScore(0.75)
.build();
var result = vectorStore.search(req);
return result.matches().stream()
.map(match -> {
long id = Long.parseLong(
match.embedded().text().replace(”product:”, “”));
return new ProductMatch(ProductEntity.findById(id), match.score());
})
.toList();
}
}Domain Object and DTO
ProductEntity is the JPA model behind the products table. It uses Quarkus Hibernate ORM with Panache, so you get an id, persist(), and findById() out of the box. The entity stores the product name, the raw image bytes as a lazy-loaded BLOB (kept out of JSON with @JsonIgnore), a createdAt timestamp set via @PrePersist, and optional metadata in a PostgreSQL JSONB column. The actual embeddings aren’t stored here—they live in the product_embeddings table managed by the pgvector store. This keeps metadata and image retrieval simple while letting vector search operate on its own optimized structure.
package com.example.embeddings;
import io.quarkus.hibernate.orm.panache.PanacheEntity;
import jakarta.persistence.*;
import org.hibernate.annotations.JdbcTypeCode;
import org.hibernate.type.SqlTypes;
import com.fasterxml.jackson.annotation.JsonIgnore;
import java.time.LocalDateTime;
@Entity
@Table(name = “products”)
public class ProductEntity extends PanacheEntity {
@Column(nullable = false)
public String name;
@Lob
@Basic(fetch = FetchType.LAZY)
@Column(nullable = false)
@JsonIgnore
public byte[] imageData;
@Column(nullable = false)
public LocalDateTime createdAt;
@JdbcTypeCode(SqlTypes.JSON)
@Column(columnDefinition = “jsonb”)
public String metadata;
@PrePersist
void prePersist() {
if (createdAt == null) {
createdAt = LocalDateTime.now();
}
}
}And the simple record:
package com.example.embeddings;
public record ProductMatch(
com.example.embeddings.ProductEntity product,
double similarityScore) {
}
REST Endpoints
ProductResource provides the HTTP API for the image search service. It exposes two endpoints under /api/products using RESTEasy Reactive. The /upload endpoint accepts multipart form data with a product name and an image file. It reads the image bytes, hands everything to ProductImageService.addProduct(), and returns the new product’s ID and name as JSON. The /search endpoint accepts a query image and an optional limit parameter (default is 5). It reads the image bytes, calls ProductImageService.findSimilar(), and returns a list of ProductMatch results ranked by similarity. Both endpoints use @RestForm and FileUpload to handle file uploads cleanly. This class is the REST layer that connects clients to the ONNX embedding and pgvector search pipeline.
package com.example.embeddings;
import java.io.IOException;
import java.nio.file.Files;
import java.util.List;
import java.util.Map;
import org.jboss.resteasy.reactive.RestForm;
import org.jboss.resteasy.reactive.multipart.FileUpload;
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.DefaultValue;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.QueryParam;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
@Path(”/api/products”)
public class ProductResource {
@Inject
ProductImageService service;
@POST
@Consumes(MediaType.MULTIPART_FORM_DATA)
@Path(”/upload”)
public Response upload(
@RestForm(”name”) String name,
@RestForm(”image”) FileUpload file) throws IOException {
byte[] bytes = Files.readAllBytes(file.uploadedFile());
ProductEntity p = service.addProduct(name, bytes);
return Response.ok(Map.of(”id”, p.id, “name”, p.name)).build();
}
@POST
@Consumes(MediaType.MULTIPART_FORM_DATA)
@Path(”/search”)
public List<ProductMatch> search(
@RestForm(”image”) FileUpload file,
@QueryParam(”limit”) @DefaultValue(”5”) int limit) throws IOException {
byte[] bytes = Files.readAllBytes(file.uploadedFile());
return service.findSimilar(bytes, limit);
}
}Test the Application
Start your application with:
quarkus devAnd run:
curl -X POST http://localhost:8080/api/products/upload \
-F “name=Red Sneakers” \
-F “image=@product1.jpg” \
-H “Accept: application/json”You should see a response like:
{
“id”: 1,
“name”: “Red Sneakers”
}Do the same with more images. Like running shoes and coffee makers and and and.
You can check that the data exists in the db. List your container processes with:
podman psGrab the id of the postgresql container and:
podman exec -e PGPASSWORD=quarkus <CONTAINER_ID> psql quarkus -U quarkus -c “SELECT embedding_id, array_length(embedding::real[], 1) as embedding_dimension FROM product_embeddings;”You’ll see something like this:
embedding_id | embedding_dimension
--------------------------------------+---------------------
6a4b3b29-4000-4655-b922-044a0bb1ae2b | 768
39d114d5-66cf-4ec7-bd67-7336281059fb | 768
e5b4df09-5979-4b94-bbe1-6dfce5c98624 | 768
(3 rows)Search for Similar Images
Let’s search using blue sneakers now (blue-sneakers.jpg):
curl -X POST http://localhost:8080/api/products/search \
-F “image=@blue-sneakers.jpg” \
-F “limit=5” \
-H “Accept: application/json”And the result should show you every image you uploaded that is similar.
[
{
“product”: {
“id”: 3,
“name”: “Red Sneakers”,
“createdAt”: “2025-11-16T15:04:42.511709”,
“metadata”: null
},
“similarityScore”: 0.8519786491400421
},
{
“product”: {
“id”: 1,
“name”: “Running Shoe”,
“createdAt”: “2025-11-16T15:04:05.851638”,
“metadata”: null
},
“similarityScore”: 0.8154390518287324
}
]ONNX vs. Other Approaches
When building an image similarity system, the choice of embedding strategy has major implications for latency, cost, operational risk, and long-term maintainability.
In enterprise environments, teams often start with cloud APIs and later discover that embedding generation becomes a cost center, a latency bottleneck, or a compliance problem.
This section compares three realistic options used in production today and highlights when ONNX is the right choice.
ONNX Runtime
Latency: 20–50 ms
Cost: $0
Offline: Yes
Accuracy: High
Setup complexity: Medium
ONNX Runtime runs the CLIP model directly inside your Quarkus application.
The main strengths:
Fast inference on CPUs (no GPU required)
Predictable performance regardless of network conditions
Zero per-request cost
Fully offline, ideal for air-gapped or regulated deployments
Works cleanly in a JVM microservice without Python
Accuracy is slightly below the very latest cloud models but strong enough for most product catalogs, asset management, and similarity search workloads. Setup requires downloading the model and adding a preprocessing pipeline, but once configured, it is stable and operationally lightweight.
Best for: Enterprise systems needing low cost, consistent latency, and full control.
OpenAI CLIP API
Latency: 200 ms and up
Cost: $$$ per request
Offline: No
Accuracy: Very High
Setup complexity: Easy
This was the simplest option for many teams before ONNX and pgvector became mainstream.
Benefits:
No infrastructure to manage
Slightly higher accuracy due to continuous improvements
Reliable embeddings for general-purpose similarity
Drawbacks:
High cumulative cost at scale
Adds 100–300 ms of network latency
Requires internet access, which many enterprises cannot allow
Vendor lock-in considerations
Cloud inference is convenient, but for image-heavy workloads—retail, manufacturing, insurance—it becomes expensive quickly.
Best for: Prototyping or low-volume applications where latency and cost are less critical.
Ollama Vision Models (LLaVA, etc.)
Latency: 1–3 seconds
Cost: $0
Offline: Yes
Accuracy: Medium
Setup complexity: Easy
Ollama is excellent for local LLM inference, but its vision models are designed for image descriptions, not vector embeddings.
That introduces several challenges:
Embeddings must be simulated by embedding the generated caption, which is inaccurate
Inference is slow (seconds per image), unsuitable for real-time search
Variability in descriptions reduces search quality
Not supported by pgvector as native vectors
Ollama is fantastic for multimodal agents and summarization pipelines, but not for visual similarity.
Best for: Image captioning, annotation, and multimodal reasoning — not vector search.
Next Steps
Extend your system with:
Hybrid search (visual + text metadata)
Fine-tuning CLIP on domain data
Multimodal RAG with LangChain4j retrievers
Qute-based UI for visual search results
Prometheus metrics for embedding latency
ONNX brings true AI capability into the JVM.
LangChain4j and pgvector turn that capability into something production-ready. Fast, predictable, and fully local. Together, they give Java developers a practical, enterprise-grade image search engine that runs without cloud dependencies and fits naturally into modern Quarkus applications.
Hey Markus, I am following you for some time now and I very much appreciate the ideas you come up with and the level of details you explain and show how the ideas are implemented. Keep up the good work. I wish you all the best with your publication.
Best Michael
Very interesting Article, Markus
Is Latency: 20–50 ms the benchmark?