

Charting Twain: Building a Character Interaction Graph with Quarkus, OpenNLP, and a local Ollama Model
Uncover hidden dynamics in Huckleberry Finn using Java, sentiment analysis, and modern NLP.


What if you could analyze a classic novel not just for words, but for relationships? In this hands-on tutorial, you'll build a powerful text analytics application with Quarkus that can extract characters, sentiment, and visualize interactions across the story.
We’ll analyze Mark Twain’s “Adventures of Huckleberry Finn,” create an interactive REST API, and generate a dynamic SVG graph of character relationships.
Project Setup with Quarkus
Make sure you have Java 17+ and Maven 3.8+ installed.
Generate the Quarkus Project
Open your terminal and create a new Quarkus app:
mvn io.quarkus.platform:quarkus-maven-plugin:create \
-DprojectGroupId=org.example \
-DprojectArtifactId=text-analytics \
-DclassName="org.example.BookResource" \
-Dpath="/book" \
-Dextensions="rest-jackson, quarkus-langchain4j-ollama"
cd text-analyticsIf you want to get started with a ready-to-go project, just check out my Github repository and clone it.
Add Apache OpenNLP
In pom.xml, add the OpenNLP dependency:
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-tools</artifactId>
<version>2.5.4</version>
</dependency>Get the Book and NLP Models
Book: Download “Adventures of Huckleberry Finn” from Project Gutenberg. Save the
.txtfile tosrc/main/resources/huck-finn.txt.Models: Download the following from the OpenNLP Model Zoo:
opennlp-en-ud-ewt-sentence-1.3-2.5.4.bin(sentence detector)opennlp-en-ud-ewt-tokens-1.3-2.5.4.bin(tokenizer)en-ner-person.bin(person name finder)
Place the models in:
src/main/resources/models/Configure the Ollama Model in src/main/resources/application.properties
quarkus.langchain4j.ollama.chat-model.model-id=llama3:8b
quarkus.langchain4j.ollama.timeout=120sBuilding the Text Analytics Service
Now we’ll build the core of our application.
Create src/main/java/org/example/TextAnalyticsService.java and paste in the below code. This service will:
Load the book and NLP models once at startup
Provide basic analysis: word count, top words, named people
Analyze sentiment for character interactions
Generate a graph data model of interactions (with nodes and edges)
We also define a set of core characters and their aliases to track meaningful interactions across the text.
package org.example;
import java.io.IOException;
import java.io.InputStream;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.TreeSet;
import java.util.function.Function;
import java.util.stream.Collectors;
import dev.langchain4j.model.chat.ChatModel;
import io.quarkus.logging.Log;
import io.quarkus.runtime.Startup;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
@ApplicationScoped
@Startup
public class TextAnalyticsService {
// --- Records for Graph Data Structure ---
public record Node(String id, String label) {
}
public record Edge(String source, String target, double sentiment, int weight) {
}
public record GraphData(List<Node> nodes, List<Edge> edges) {
}
// --- Injected Ollama Model ---
@Inject
ChatModel chatModel;
private String bookText;
private SentenceDetectorME sentenceDetector;
private TokenizerME tokenizer;
private NameFinderME nameFinder;
private final Set<String> stopWords = Set.of(
"a", "an", "and", "the", "in", "on", "of", "to", "is", "it", "i", "you", "he", "she");
private static final Map<String, List<String>> MAIN_CHARACTERS = Map.of(
"Huck", List.of("huck", "huckleberry", "Tom Sawyer's Comrade", "Huck Finn", "Sarah Williams", "Sarah Mary Williams George Elexander Peters", "George Peters"),
"Tom", List.of("tom", "tom sawyer", "Sawyer", "Sawyer's"),
"Jim", List.of("jim", "Ole Jim", "Watson's Jim", "Watson's", "Mars Tom"),
"Miss Watson", List.of("miss watson"),
"Widow Douglas", List.of("widow douglas"),
"The Duke", List.of("duke"),
"Harvey Wilks", List.of("king", "Harvey"));
public TextAnalyticsService() throws IOException {
Log.info("Loading resources...");
try (InputStream bookStream = getClass().getResourceAsStream("/huck-finn.txt")) {
this.bookText = new String(bookStream.readAllBytes(), StandardCharsets.UTF_8);
}
try (InputStream sentModelIn = getClass()
.getResourceAsStream("/models/opennlp-en-ud-ewt-sentence-1.3-2.5.4.bin");
InputStream tokenModelIn = getClass()
.getResourceAsStream("/models/opennlp-en-ud-ewt-tokens-1.3-2.5.4.bin");
InputStream personModelIn = getClass().getResourceAsStream("/models/en-ner-person.bin")) {
this.sentenceDetector = new SentenceDetectorME(new SentenceModel(sentModelIn));
this.tokenizer = new TokenizerME(new TokenizerModel(tokenModelIn));
this.nameFinder = new NameFinderME(new TokenNameFinderModel(personModelIn));
}
Log.info("Resources loaded successfully!");
}
// --- Basic Analysis Methods ---
public long getWordCount() {
return Arrays.stream(tokenizer.tokenize(this.bookText.toLowerCase())).count();
}
public Map<String, Long> getTopWords(int limit) {
String[] tokens = tokenizer.tokenize(this.bookText.toLowerCase());
return Arrays.stream(tokens)
.filter(word -> word.matches("[a-zA-Z]+"))
.filter(word -> !stopWords.contains(word))
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()))
.entrySet().stream()
.sorted(Map.Entry.<String, Long>comparingByValue().reversed())
.limit(limit)
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (e1, e2) -> e1, LinkedHashMap::new));
}
public Set<String> findPeople() {
Set<String> names = new HashSet<>();
String[] sentences = sentenceDetector.sentDetect(this.bookText);
for (String sentence : sentences) {
String[] tokens = tokenizer.tokenize(sentence);
Span[] nameSpans = nameFinder.find(tokens);
names.addAll(Arrays.asList(Span.spansToStrings(nameSpans, tokens)));
}
nameFinder.clearAdaptiveData();
return names;
}
// --- Character Interaction Graph Methods ---
public GraphData getInteractionGraph() {
Map<Set<String>, List<Double>> interactions = new HashMap<>();
String[] sentences = sentenceDetector.sentDetect(bookText);
for (String sentence : sentences) {
Set<String> presentCharacters = findMainCharactersInText(sentence.toLowerCase());
if (presentCharacters.size() >= 2) {
double sentimentScore = analyzeSentimentWithLLM(sentence);
List<String> charList = new ArrayList<>(presentCharacters);
for (int i = 0; i < charList.size(); i++) {
for (int j = i + 1; j < charList.size(); j++) {
Set<String> pair = new TreeSet<>(Set.of(charList.get(i), charList.get(j)));
interactions.computeIfAbsent(pair, k -> new ArrayList<>()).add(sentimentScore);
}
}
}
}
return buildGraphDataFromInteractions(interactions);
}
private Set<String> findMainCharactersInText(String text) {
return MAIN_CHARACTERS.entrySet().stream()
.filter(entry -> entry.getValue().stream().anyMatch(text::contains))
.map(Map.Entry::getKey)
.collect(Collectors.toSet());
}
/**
* Uses the injected Ollama chat model to analyze sentiment.
* This method performs "prompt engineering" to get a structured response.
*/
private double analyzeSentimentWithLLM(String text) {
String prompt = String.format(
"You are a sentiment analysis expert. Analyze the following historic text and respond with ONLY a single number "
+
"representing the sentiment: 2 for very positive, 1 for positive, 0 for neutral, " +
"-1 for negative, or -2 for very negative. Do not provide any other text or explanation. " +
"ONLY RESPONSE WITH A SINGLE NUMBER" +
"The text is: \"%s\"",
text);
try {
// Send the prompt to the LLM
String response = chatModel.chat(prompt);
// The LLM should return just a number. We parse it.
return Double.parseDouble(response.trim());
} catch (Exception e) {
// If the LLM response is not a number or an error occurs, default to neutral.
Log.errorf("Could not parse sentiment from LLM response: " + e.getMessage());
return 0.0;
}
}
private GraphData buildGraphDataFromInteractions(Map<Set<String>, List<Double>> interactions) {
List<Node> nodes = MAIN_CHARACTERS.keySet().stream()
.map(name -> new Node(name, name))
.toList();
List<Edge> edges = interactions.entrySet().stream()
.map(entry -> {
List<String> pair = new ArrayList<>(entry.getKey());
double averageSentiment = entry.getValue().stream().mapToDouble(d -> d).average().orElse(0.0);
int weight = entry.getValue().size();
return new Edge(pair.get(0), pair.get(1), averageSentiment, weight);
})
.toList();
return new GraphData(nodes, edges);
}
}Exposing REST Endpoints
We’ll now make the service accessible over HTTP.
Update the BookResource class at src/main/java/org/example/BookResource.java with the below code.
package org.example;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.QueryParam;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
@Path("/book")
public class BookResource {
@Inject
TextAnalyticsService service;
@GET
@Path("/word-count")
@Produces(MediaType.APPLICATION_JSON)
public Map<String, Long> getWordCount() {
return Map.of("totalWords", service.getWordCount());
}
@GET
@Path("/top-words")
@Produces(MediaType.APPLICATION_JSON)
public Map<String, Long> getTopWords(@QueryParam("limit") int limit) {
return service.getTopWords(limit > 0 ? limit : 10);
}
@GET
@Path("/people")
@Produces(MediaType.APPLICATION_JSON)
public Set<String> getPeople() {
return service.findPeople();
}
@GET
@Path("/interaction-graph")
@Produces(MediaType.APPLICATION_JSON)
public TextAnalyticsService.GraphData getInteractionGraph() {
return service.getInteractionGraph();
}
@GET
@Path("/interaction-graph/view")
@Produces("image/svg+xml")
public Response getInteractionGraphSvg() {
TextAnalyticsService.GraphData graphData = service.getInteractionGraph();
String svg = generateSvg(graphData);
return Response.ok(svg).build();
}
// Helper method to generate an SVG from graph data
private String generateSvg(TextAnalyticsService.GraphData graphData) {
StringBuilder svg = new StringBuilder();
int width = 1000, height = 800;
svg.append(String.format(
"<svg width=\"%d\" height=\"%d\" xmlns=\"http://www.w3.org/2000/svg\" style=\"background-color:#f0f0f0; font-family: sans-serif;\">",
width, height));
// Node positions in a circle
Map<String, int[]> positions = new HashMap<>();
int numNodes = graphData.nodes().size();
int centerX = width / 2, centerY = height / 2, radius = 300;
for (int i = 0; i < numNodes; i++) {
String id = graphData.nodes().get(i).id();
double angle = 2 * Math.PI * i / numNodes;
int x = (int) (centerX + radius * Math.cos(angle));
int y = (int) (centerY + radius * Math.sin(angle));
positions.put(id, new int[] { x, y });
}
// Draw edges
svg.append("<g id=\"edges\">");
for (var edge : graphData.edges()) {
int[] pos1 = positions.get(edge.source());
int[] pos2 = positions.get(edge.target());
String color = edge.sentiment() > 0.5 ? "#2a9d8f" : (edge.sentiment() < -0.5 ? "#e76f51" : "#8d99ae");
double strokeWidth = 1 + Math.log(edge.weight()); // Log scale for better visibility
svg.append(String.format(
"<line x1=\"%d\" y1=\"%d\" x2=\"%d\" y2=\"%d\" stroke=\"%s\" stroke-width=\"%.2f\" />",
pos1[0], pos1[1], pos2[0], pos2[1], color, strokeWidth));
}
svg.append("</g>");
// Draw nodes
svg.append("<g id=\"nodes\">");
for (var node : graphData.nodes()) {
int[] pos = positions.get(node.id());
svg.append(String.format(
"<circle cx=\"%d\" cy=\"%d\" r=\"30\" fill=\"#edf2f4\" stroke=\"#2b2d42\" stroke-width=\"2\" />",
pos[0], pos[1]));
svg.append(String.format(
"<text x=\"%d\" y=\"%d\" text-anchor=\"middle\" dy=\".3em\" fill=\"#2b2d42\" font-size=\"14\">%s</text>",
pos[0], pos[1], node.label()));
}
svg.append("</g>");
svg.append("</svg>");
return svg.toString();
}
}It adds endpoints to:
/book/word-count: total word count/book/top-words?limit=N: most frequent words (excluding stopwords)/book/people: named person entities/book/interaction-graph: character interactions as raw JSON/book/interaction-graph/view: an SVG rendering of the interaction graph
The /view endpoint dynamically lays out the graph with:
Circular node positioning
Color-coded edges by sentiment
Line thickness by interaction frequency
Testing the API
Start Quarkus:
./mvnw quarkus:devGet Total Word Count
curl http://localhost:8080/book/word-countExpected response:
{"totalWords":135405}Top 5 Words
curl "http://localhost:8080/book/top-words?limit=5"Response:
{"was":2039,"that":1058,"but":1029,"so":935,"for":876}Named People
curl http://localhost:8080/book/peopleReturns a set of detected names like "tom sawyer", "jim", "pap".
Visualizing Character Interactions
Now comes the most interesting part: Mapping out social relationships between characters based on co-occurrence in sentences and their associated sentiment.
curl http://localhost:8080/interaction-graphThe /interaction-graph endpoint returns data like:
{
"nodes": [
{"id": "Tom", "label": "Tom"},
{"id": "Pap", "label": "Pap"}
],
"edges": [
{
"source": "Huck",
"target": "Pap",
"sentiment": -1.0,
"weight": 28
},
{
"source": "Huck",
"target": "Jim",
"sentiment": 0.67,
"weight": 112
}
]
}
And the /interaction-graph/view endpoint gives you an SVG visualization like this (open in browser):
http://localhost:8080/book/interaction-graph/view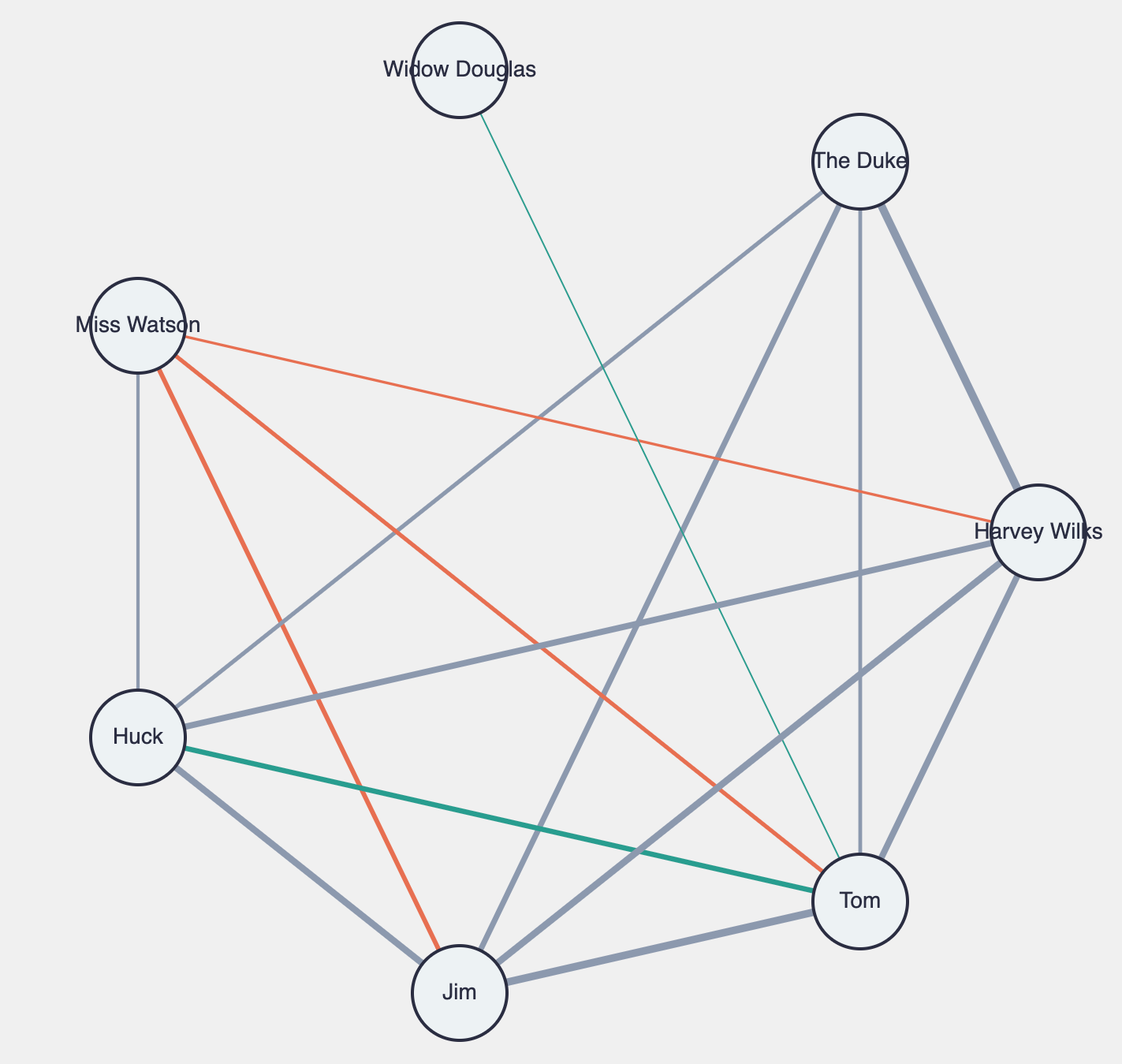
It shows:
Circles for each main character
Lines between characters who co-occur
Line color: green for positive, red for negative, gray for neutral
Line thickness: more interactions = thicker line
This is especially powerful for literature students, researchers, or hobbyists trying to understand social dynamics in classic texts.
Understanding Character Detection: Discovery vs. Focused Analysis
One common question when exploring this application is why it uses two different approaches to identify characters in the text. The answer lies in a fundamental distinction between discovery and focused analysis, each serving a different purpose in natural language processing workflows.
Raw Discovery with Named Entity Recognition (NER)
The /book/people endpoint uses a pre-trained Person Named Entity Recognition (NER) model from OpenNLP. Its role is to discover as many person references as possible across the entire novel. It scans the text and extracts any token or phrase it recognizes as a person’s name. This yields a comprehensive list, including common names like “Tom,” compound forms like “Tom Sawyer,” and sometimes even misclassifications or characters who appear only once.
This endpoint is intentionally broad. It’s useful for exploratory analysis, helping you understand the scope and limitations of the NER model. However, its results are noisy and redundant. Names like “Sawyer” and “Tom Sawyer” may be listed separately, even though they refer to the same person. For visualization or structured insights, this level of raw output becomes more of a liability than an asset.
Curated Focus with Main Character Mapping
In contrast, the /book/interaction-graph endpoint is designed for focused analysis. It doesn't rely on dynamic NER outputs. Instead, it uses a hand-curated MAIN_CHARACTERS map. A domain-specific list of key characters and their known aliases (e.g., “huck,” “huckleberry” → “Huck”). This allows us to perform light coreference resolution and disambiguation, which the raw NER model alone cannot achieve reliably.
By narrowing the scope to just the main characters, we solve two problems at once:
Identity Resolution: Without normalization, “Tom,” “Tom Sawyer,” and “Sawyer” would appear as three different nodes in the graph. By unifying aliases under a single canonical name, the app maintains semantic integrity in the interaction data.
Visual Clarity: Including every named character in a network graph would create visual chaos. By reducing the graph to a small set of central figures, we get a clean, interpretable visualization of the story’s emotional and social structure.
This dual-layer design mirrors real-world NLP practices. The findPeople() method gives you the unfiltered view, while the MAIN_CHARACTERS map applies human curation to support meaningful, story-driven insights.
What Can Happen Sometimes
Large Language Models (LLMs) often struggle with analyzing historical texts that include outdated or offensive language, such as racial slurs or colonial stereotypes. Many mainstream models, including those from OpenAI or Anthropic, are explicitly aligned to avoid generating responses that could be interpreted as endorsing or amplifying harmful content. This can lead to refusals like: "I cannot provide a sentiment analysis of a text that contains racist slurs." While well-intentioned from a safety and alignment perspective, such refusals are problematic for researchers, educators, and developers working with public domain literature, historical documents, or social data that reflect the biases of their time. In these contexts, neutral, analytical processing, not endorsement, is required. More suitable options include open-source models like Gemma, which can be run locally with stricter guardrails under the developer’s control. These models allow for critical analysis of complex texts while maintaining the ability to audit, constrain, and contextualize outputs in research-safe environments.
What You Learned
You’ve built a full Quarkus-based application that:
Loads and processes a novel at startup
Uses Apache OpenNLP to tokenize, segment, and extract entities
Performs sentiment analysis per sentence
Aggregates and visualizes social interactions between characters
Exposes the full functionality via a modern JSON and SVG API
Next Steps and Ideas
Want to extend this? Try one of these:
Use Qute templates to make a beautiful web UI
Add support for other novels by uploading new
.txtfilesStore results in PostgreSQL using Panache for persistence
Export graphs to PNG/PDF using Batik or Java2D
This project blends traditional NLP with modern Java architectures and LLMs. You’ve created a literary analytics engine powered by Java.
Let your imagination run wild. Twain would’ve approved.
Hi Markus
I got this strange behavior with Ollama configuration:
"examples before" I decided to move .ollama folder to my second HHDD, and for that
I defined: "export OLLAMA_MODELS=/pathTo/ollama" in my .zshrc file.
At first, it was working fine, but some how since a I tried this tutorial, the variable is no longer recognized, neither the othe examples I already did.
Any clue about this ? or where would be the best play to ask :D