

Your Second Reactive Messaging App: What Production Systems Actually Need
A realistic Java walkthrough showing validation, retries, idempotency, and Kafka-backed workflows with Quarkus.

Your first reactive messaging app did answers one question:
“How do messages flow?”
Your second app must answer harder ones:
What happens when messages are duplicated?
What happens when downstream services fail?
How do retries stop before taking the system down?
How do we prove what was processed and what wasn’t?
This tutorial builds a claims intake pipeline that assumes things go wrong and keeps working anyway. We will deliberately introduce failures, duplicates, and delays, and then design the system so none of that breaks it.
This is not a Kafka deep dive.
This is about architectural discipline in event-driven Java.
What We’re Building
A realistic, production-shaped pipeline:
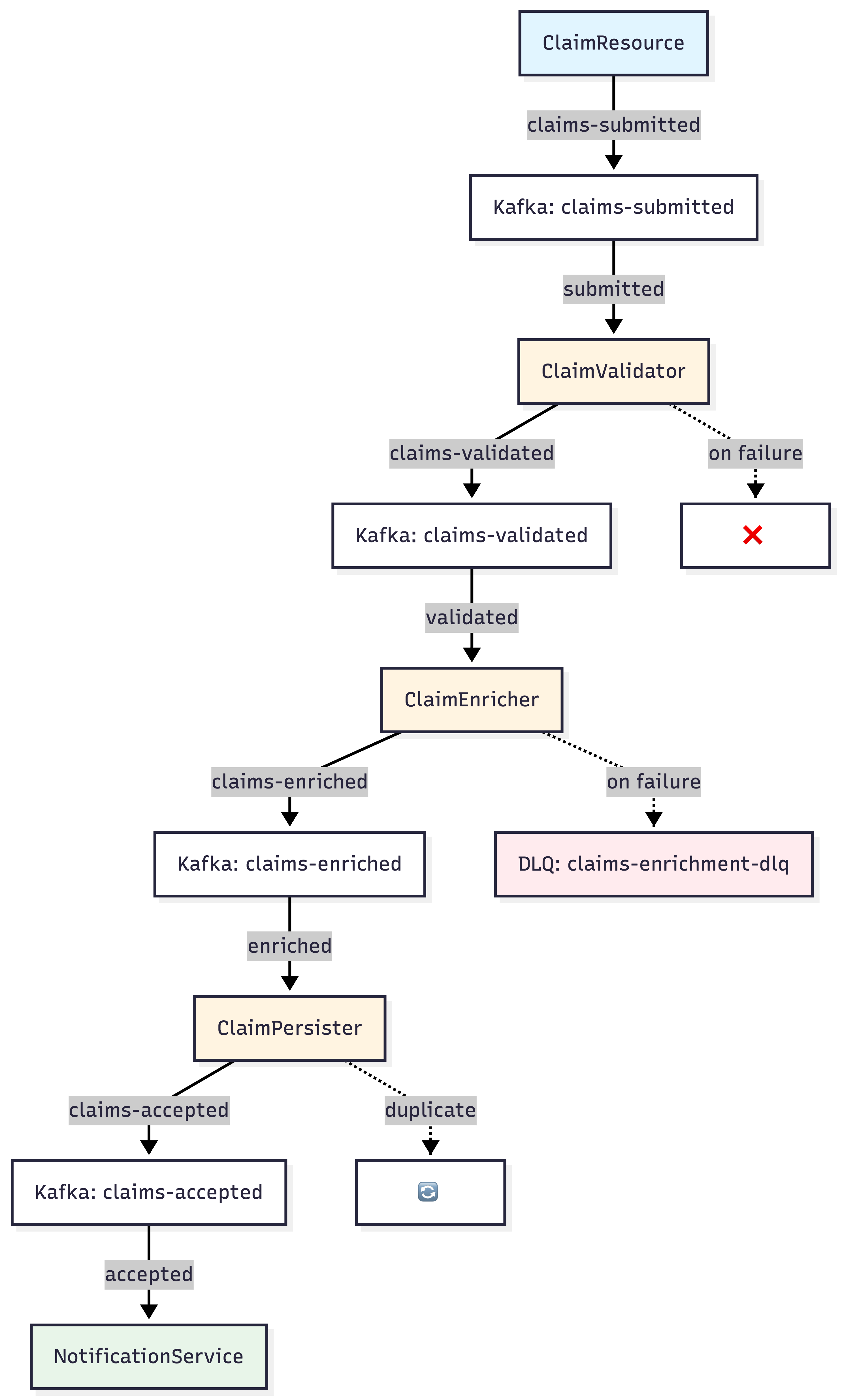
Failure paths:
Invalid data → ignored
Transient failures → retry with backoff
Permanent failures → dead-letter topic
Duplicate events → safely ignored
Key assumptions:
At-least-once delivery
Messages can arrive out of order
External systems fail
Operators need to understand what happened
Prerequisites and Versions
Java 21 (Java 17 works, but pick one and stick to it)
Maven 3.9+
Quarkus 3.x
Podman or Docker (optional, Dev Services handles everything)
No Kafka or PostgreSQL installation required.
Bootstrap the Project
Create the project yourself and follow along or grab the code from my Github repository.
quarkus create app com.acme:claims-intake \
--extensions="quarkus-messaging-kafka, \
jdbc-postgresql, \
hibernate-orm-panache, \
rest-jackson"
cd claims-intakeWhy these extensions:
smallrye-reactive-messaging-kafka– real broker semanticshibernate-orm-panache– explicit persistence and idempotencyjdbc-postgresql– audit-friendly storagerest-jackson– REST with JSON
Domain Events (Be Explicit)
Events are contracts. Treat them as such.
ClaimSubmitted
package com.acme.claims.events;
public record ClaimSubmitted(
String eventId,
String claimId,
String customerId,
double amount
) {}ClaimValidated
package com.acme.claims.events;
import com.fasterxml.jackson.annotation.JsonProperty;
public record ClaimValidated(
@JsonProperty("eventId") String eventId,
@JsonProperty("claimId") String claimId,
@JsonProperty("customerId") String customerId,
@JsonProperty("amount") double amount) {
}Why are we using @JsonProperty all over here?
In the Kafka ecosystem, SerDes (Serializer and Deserializer) act as the critical translators between your application and the broker. Kafka itself is agnostic to data types; it only stores and transmits raw byte arrays. Your Quarkus application, however, works with strongly typed Java Objects (like the ClaimAccepted record).
A Serializer converts your Java Object into JSON bytes (Encoding) when you send a message.
A Deserializer converts those JSON bytes back into a Java Object (Decoding) when you receive a message.
In Quarkus, you generally do not need to write or even configure manual serializers and deserializers for simple Java records like ClaimAccepted. Quarkus can handle this automatically using Jackson (JSON).
However, if you need to strictly define them, e.g. for a Dead Letter Queue or other reasons, you have to write and configure this yourself.
I use @JsonProperty on Java Records for two main reasons:
Visibility: Unlike traditional classes, Java Records do not follow the standard “Getter” naming convention (e.g.,
getClaimId()vsclaimId()). Without@JsonProperty(or specific compiler flags), the JSON Serializer might fail to “see” the fields, resulting in it writing an empty JSON object{}to your DLQ.Explicit Mapping: It guarantees that the field names in your Java code (e.g.,
claimId) map exactly to the JSON keys expected by downstream systems (e.g.,"claim_id"), preventing data corruption during the error-handling process.
@JsonProperty is optional if you compile with the -parameters flag, which Quarkus does by default. So, I am just being overly explicit here. While we are here, let’s also add the SerDes for this particular event.
ClaimValidatedSerializer
package com.acme.claims.events;
import io.quarkus.kafka.client.serialization.ObjectMapperSerializer;
public class ClaimValidatedSerializer extends ObjectMapperSerializer<ClaimValidated> {
}ClaimValidatedDeserializer
package com.acme.claims.events;
import io.quarkus.kafka.client.serialization.ObjectMapperDeserializer;
public class ClaimValidatedDeserializer extends ObjectMapperDeserializer<ClaimValidated> {
public ClaimValidatedDeserializer() {
super(ClaimValidated.class);
}
}ClaimAccepted
package com.acme.claims.events;
public record ClaimAccepted(
String eventId,
String claimId,
String status
) {}Why eventId matters
Kafka does not guarantee exactly-once for consumers
Retries and replays are normal
Idempotency starts with stable identifiers
REST Ingress (Thin by Design)
REST should emit, not orchestrate.
package com.acme.claims.boundary;
import org.eclipse.microprofile.reactive.messaging.Channel;
import org.eclipse.microprofile.reactive.messaging.Emitter;
import com.acme.claims.events.ClaimSubmitted;
import io.quarkus.logging.Log;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.POST;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
@Path("/claims")
@Consumes(MediaType.APPLICATION_JSON)
@Produces(MediaType.APPLICATION_JSON)
@ApplicationScoped
public class ClaimResource {
@Channel("claims-submitted")
Emitter<ClaimSubmitted> emitter;
@POST
public Response submit(ClaimSubmitted claim) {
Log.infof("[SUBMITTED] eventId=%s, claimId=%s, customerId=%s, amount=%.2f",
claim.eventId(), claim.claimId(), claim.customerId(), claim.amount());
emitter.send(claim);
return Response.accepted().entity(claim).build();
}
}No validation.
No database calls.
No waiting for downstream systems.
Validation Stage
Validation is synchronous and cheap.
package com.acme.claims.processing;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import com.acme.claims.events.ClaimSubmitted;
import com.acme.claims.events.ClaimValidated;
import io.quarkus.logging.Log;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
public class ClaimValidator {
@Incoming("submitted")
@Outgoing("claims-validated")
public ClaimValidated validate(ClaimSubmitted claim) {
if (claim.amount() <= 0) {
Log.errorf("[VALIDATION FAILED] eventId=%s, claimId=%s - Amount must be positive (amount=%.2f)",
claim.eventId(), claim.claimId(), claim.amount());
throw new IllegalArgumentException(
"Claim amount must be positive");
}
Log.infof("[VALIDATED] eventId=%s, claimId=%s, amount=%.2f",
claim.eventId(), claim.claimId(), claim.amount());
return new ClaimValidated(
claim.eventId(),
claim.claimId(),
claim.customerId(),
claim.amount());
}
}We intentionally throw exceptions.
Failure handling comes later.
Enrichment with Failure Injection
This stage simulates an unstable external dependency.
package com.acme.claims.processing;
import java.util.concurrent.ThreadLocalRandom;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import com.acme.claims.events.ClaimValidated;
import io.quarkus.logging.Log;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
public class ClaimEnricher {
private static final int MAX_ATTEMPTS = 3;
@Incoming("validated")
@Outgoing("claims-enriched")
public ClaimValidated enrich(ClaimValidated claim) {
Log.infof("[ENRICHING] eventId=%s, claimId=%s - Calling external service...",
claim.eventId(), claim.claimId());
int attempt = 0;
while (true) {
try {
attempt++;
if (attempt > 1) {
Log.infof("[ENRICHING RETRY] eventId=%s, claimId=%s - Attempt %d/%d",
claim.eventId(), claim.claimId(), attempt, MAX_ATTEMPTS);
}
callExternalService(claim);
Log.infof("✨ [ENRICHED] eventId=%s, claimId=%s",
claim.eventId(), claim.claimId());
return claim;
} catch (RuntimeException ex) {
if (attempt >= MAX_ATTEMPTS) {
Log.errorf("[ENRICHMENT FAILED] eventId=%s, claimId=%s - Max attempts reached, routing to DLQ",
claim.eventId(), claim.claimId());
throw ex; // routed to DLQ
}
Log.warnf("[ENRICHMENT RETRY] eventId=%s, claimId=%s - External service timeout, retrying...",
claim.eventId(), claim.claimId());
backoff(attempt);
}
}
}
private void callExternalService(ClaimValidated claim) {
if (ThreadLocalRandom.current().nextInt(4) == 0) {
throw new RuntimeException("External service timeout");
}
}
private void backoff(int attempt) {
try {
Thread.sleep(500L * attempt);
} catch (InterruptedException ignored) {
}
}
}This will fail roughly 25% of the time.
That is intentional.
Handling Failures Correctly: DLQ Instead of Blind Retries
In a Kafka-backed reactive messaging pipeline, failures must be handled deliberately.
Unlike some messaging systems, Kafka does not retry failed records automatically, and Quarkus does not invent a retry strategy on top of it. This is intentional. Automatic retries at the connector level would block partitions, amplify failures, and hide poison messages.
Quarkus therefore exposes three explicit failure strategies for Kafka consumers:
fail-fast (default): stop the application and mark it unhealthy
ignore: skip the failing record and continue
dead-letter-queue (DLQ): forward the failing record to another topic
For production systems, DLQ is the only safe default.
Why Retries Do Not Belong in the Connector
Retries are not a messaging concern. They are a business and operational concern.
Only the application knows:
which failures are transient
how long it is safe to wait
how many attempts are acceptable
whether the operation is idempotent
Blind retries at the connector level would:
block message consumption for an entire partition
retry poison messages forever
violate ordering guarantees
make failures invisible until the system collapses
Kafka gives you durability and ordering.
You must provide the retry semantics.
Configuring The Channels
In Quarkus Reactive Messaging, channels connect processing stages. Each stage consumes from one channel and publishes to another, forming a pipeline.
Channel naming convention:
Outgoing channels use the Kafka topic name (e.g., claims-submitted, claims-validated)
Incoming channels use stage names (e.g., submitted, validated, enriched)
Both map to the same Kafka topic, so the topic name is the source of truth
This avoids using the same channel name for both incoming and outgoing, which Quarkus doesn’t allow.
Add the following to application.properties:
# --- Channel Configuration ---
# Outgoing channels use topic names, incoming channels use stage names
# Both map to the same Kafka topics
# Stage 1: ClaimResource -> ClaimValidator (topic: claims-submitted)
mp.messaging.outgoing.claims-submitted.connector=smallrye-kafka
mp.messaging.outgoing.claims-submitted.topic=claims-submitted
mp.messaging.incoming.submitted.connector=smallrye-kafka
mp.messaging.incoming.submitted.topic=claims-submitted
mp.messaging.incoming.submitted.failure-strategy=ignore
# Stage 2: ClaimValidator -> ClaimEnricher (topic: claims-validated)
mp.messaging.outgoing.claims-validated.connector=smallrye-kafka
mp.messaging.outgoing.claims-validated.topic=claims-validated
mp.messaging.incoming.validated.connector=smallrye-kafka
mp.messaging.incoming.validated.topic=claims-validated
mp.messaging.incoming.validated.value.deserializer=com.acme.claims.events.ClaimValidatedDeserializer
mp.messaging.incoming.validated.failure-strategy=dead-letter-queue
mp.messaging.incoming.validated.dead-letter-queue.topic=claims-enrichment-dlq
mp.messaging.incoming.validated.dead-letter-queue.value.serializer=com.acme.claims.events.ClaimValidatedSerializer
mp.messaging.incoming.validated.dead-letter-queue.key.serializer=org.apache.kafka.common.serialization.StringSerializer
# Stage 3: ClaimEnricher -> ClaimPersister (topic: claims-enriched)
mp.messaging.outgoing.claims-enriched.connector=smallrye-kafka
mp.messaging.outgoing.claims-enriched.topic=claims-enriched
mp.messaging.incoming.enriched.connector=smallrye-kafka
mp.messaging.incoming.enriched.topic=claims-enriched
# Stage 4: ClaimPersister -> NotificationService (topic: claims-accepted)
mp.messaging.outgoing.claims-accepted.connector=smallrye-kafka
mp.messaging.outgoing.claims-accepted.topic=claims-accepted
mp.messaging.incoming.accepted.connector=smallrye-kafka
mp.messaging.incoming.accepted.topic=claims-acceptedWith this configuration:
each processing stage is clearly identified by its incoming channel name
Kafka topics remain the source of truth for message routing
the pipeline flows through four stages: submitted → validated → enriched → accepted
failure strategies are configurable per stage: ignore for validation failures, dead-letter-queue for enrichment retries
channel names avoid conflicts since incoming and outgoing use different names
This setup provides clear separation of concerns and makes the event flow easy to follow.
Idempotent Persistence (The Core Pattern)
Database Entity
package com.acme.claims.persistence;
import io.quarkus.hibernate.orm.panache.PanacheEntityBase;
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import jakarta.persistence.Table;
@Entity
@Table(name = "processed_event")
public class ProcessedEvent extends PanacheEntityBase {
@Id
public String eventId;
public static boolean alreadyProcessed(String eventId) {
return findById(eventId) != null;
}
public static void markProcessed(String eventId) {
ProcessedEvent e = new ProcessedEvent();
e.eventId = eventId;
e.persist();
}
}This table is your truth.
Consumer with Idempotency Guard
package com.acme.claims.processing;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import com.acme.claims.events.ClaimAccepted;
import com.acme.claims.events.ClaimValidated;
import com.acme.claims.persistence.ProcessedEvent;
import io.quarkus.logging.Log;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.transaction.Transactional;
@ApplicationScoped
public class ClaimPersister {
@Incoming("enriched")
@Outgoing("claims-accepted")
@Transactional
public ClaimAccepted persist(ClaimValidated claim) {
if (ProcessedEvent.alreadyProcessed(claim.eventId())) {
Log.warnf("[DUPLICATE] eventId=%s, claimId=%s - Already processed, ignoring",
claim.eventId(), claim.claimId());
return null; // duplicate, safely ignored
}
ProcessedEvent.markProcessed(claim.eventId());
Log.infof("💾 [PERSISTED] eventId=%s, claimId=%s - Marked as processed",
claim.eventId(), claim.claimId());
ClaimAccepted accepted = new ClaimAccepted(
claim.eventId(),
claim.claimId(),
"ACCEPTED");
Log.infof("[ACCEPTED] eventId=%s, claimId=%s, status=ACCEPTED",
accepted.eventId(), accepted.claimId());
return accepted;
}
}
This is the most important method in the entire tutorial.
Exactly-once is rare.
Idempotency is mandatory.
Final Notification
package com.acme.claims.notification;
import org.eclipse.microprofile.reactive.messaging.Incoming;
import com.acme.claims.events.ClaimAccepted;
import io.quarkus.logging.Log;
import jakarta.enterprise.context.ApplicationScoped;
@ApplicationScoped
public class NotificationService {
@Incoming("accepted")
public void notify(ClaimAccepted claim) {
Log.infof("[NOTIFICATION] eventId=%s, claimId=%s, status=%s - Sending notification to customer",
claim.eventId(), claim.claimId(), claim.status());
}
}Run and Verify
Start the app:
quarkus devSubmit claims:
curl -X POST http://localhost:8080/claims \
-H "Content-Type: application/json" \
-d '{
"eventId": "evt-1",
"claimId": "claim-123",
"customerId": "cust-42",
"amount": 100.0
}'Submit duplicates.
Submit multiple claims.
Watch retries happen.
07:46:51 CLAIM SUBMITTED
eventId=evt-3 | claimId=claim-424 | customerId=cust-43 | amount=500.00
Source: REST API
07:46:52 CONSUME claims.submitted
Kafka partition initialized (claims-submitted-0)
07:46:52 CLAIM VALIDATED
eventId=evt-3 | claimId=claim-424 | amount=500.00
Processor: ClaimValidator
07:46:53 CONSUME claims.validated
Kafka partition initialized (claims-validated-0)
07:46:53 ENRICHMENT STARTED
eventId=evt-3 | claimId=claim-424
Action: Calling external enrichment service
07:46:53 ENRICHMENT TIMEOUT
eventId=evt-3 | claimId=claim-424
Action: Retrying (attempt 1/3)
07:46:53 ENRICHMENT RETRY
eventId=evt-3 | claimId=claim-424
Attempt: 2/3
07:46:53 ENRICHMENT SUCCESSFUL
eventId=evt-3 | claimId=claim-424
07:46:53 CONSUME claims.enriched
Kafka partition initialized (claims-enriched-0)
07:46:53 CLAIM PERSISTED
eventId=evt-3 | claimId=claim-424
Idempotent write confirmed
07:46:53 CLAIM ACCEPTED
eventId=evt-3 | claimId=claim-424
Status: ACCEPTED
07:46:54 CONSUME claims.accepted
Kafka partition initialized (claims-accepted-0)
07:46:54 NOTIFICATION SENT
eventId=evt-3 | claimId=claim-424
Message: Claim accepted notification deliveredExpected behavior:
Some enrichments fail, then succeed
Duplicates do not create extra DB rows
Pipeline continues processing other claims
Final notifications appear once per claim
What This App Teaches (That the First Didn’t)
Delivery is at-least-once, not exactly-once
Failure is normal, not exceptional
Retries must be bounded
Idempotency belongs in consumers
Persistence is part of messaging
Reliability is designed, not configured
Production Notes
Always include event identifiers
Use DLQs for poison messages
Treat retries as operational risk
Never assume ordering without partition strategy
Log correlation IDs
Make state visible to operators
This is your second reactive messaging app.
If you can build this, you can build systems that survive production.