

Museum Gift Shop: A Small Quarkus App with REST, Panache, and an MCP HTTP/SSE endpoint
Learn how to extend my TechXChange Demo Quarkus app with a simple online shop and an AI-ready MCP endpoints for LLM integration.

This adds a tiny online shop to our existing museum application. It sells gift-shop items tied to artworks. You’ll build clean REST endpoints with JSON, a minimal and a modern MCP server that streams inventory for a given artwork over HTTP/SSE. It’s small enough to read in one sitting and complete in an afternoon. It’s also production-minded: pinned versions, dev-friendly defaults, and clear extension points.
Why this matters
Your museum app already recognizes artworks. The next logical step is commerce. This gift-shop microservice shows how to:
Hang REST APIs and MCP tools off the same data model.
Stream inventory updates to LLM clients with HTTP/SSE.
Keep tool definitions tight so models select them reliably.
Quarkus gives you fast startup, live reload, and Dev Services for PostgreSQL. The MCP server lets AI clients discover and call your “list_inventory_by_artwork” tool via streamable http.
Prerequisites
Java 21 or newer (Java 25 works fine).
Quarkus CLI.
Podman installed. Docker also works.
PostgreSQL optional locally; Dev Services will auto-provision a container.
Project bootstrap and dependencies
Create a new module next to your existing ones in the museum folder. We’ll call it museum-giftshop.
quarkus create app com.example:museum-giftshop \
--no-code \
--extension=quarkus-rest-jackson,quarkus-hibernate-orm-panache,quarkus-jdbc-postgresql,quarkus-qute,io.quarkiverse.mcp:quarkus-mcp-server-sse
cd museum-giftshopNotes:
quarkus-rest-jacksonis the REST + Jackson extension you want today. (Quarkus)Panache simplifies entities and queries. (Quarkus)
quarkus-mcp-server-ssesupports both Streamable HTTP (/mcp) and HTTP/SSE (/mcp/sse). (docs.quarkiverse.io)
Note: You can grab the full running example from my Github repository.
Add the configuration into the application.properties
# HTTP
quarkus.http.port=8082
quarkus.http.cors=true
# DB via Dev Services
quarkus.hibernate-orm.schema-management.strategy=drop-and-create
quarkus.datasource.db-kind=postgresql
# MCP Server (SSE + Streamable HTTP)
# /mcp for Streamable HTTP (new); /mcp/sse for legacy SSE
quarkus.mcp.server.sse.root-path=/mcp
quarkus.mcp.server.traffic-logging.enabled=true
quarkus.mcp.server.traffic-logging.text-limit=500
# Keep clients alive (HTTP transports)
quarkus.mcp.server.auto-ping-interval=30S
We need a third http port for this service
add the postgress information and let Panache/Hibernate manage the schema
Configure the MCP Server appropriatly
Core implementation
Domain model
We keep it intentionally small: Artwork and ShopItem. Each ShopItem is associated with an artwork by name. Add a unique SKU, stock, and price.
package com.ibm.txc.museum.shop.domain;
import io.quarkus.hibernate.orm.panache.PanacheEntity;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import jakarta.persistence.Index;
import jakarta.persistence.Table;
@Entity
@Table(name = “artwork”, indexes = {
@Index(name = “idx_artwork_name”, columnList = “name”, unique = true)
})
public class Artwork extends PanacheEntity {
@Column(nullable = false, unique = true)
public String name;
@Column(nullable = false, unique = true)
public String code;
public static Artwork findOrCreateByName(String name) {
Artwork a = find(”name = ?1”, name).firstResult();
if (a == null) {
a = new Artwork();
a.name = name;
a.persist();
}
return a;
}
}package com.ibm.txc.museum.shop.domain;
import java.math.BigDecimal;
import io.quarkus.hibernate.orm.panache.PanacheEntity;
import jakarta.persistence.Column;
import jakarta.persistence.Entity;
import jakarta.persistence.Index;
import jakarta.persistence.Table;
@Entity
@Table(name = “shop_item”, indexes = {
@Index(name = “idx_item_artwork”, columnList = “artworkName”),
@Index(name = “idx_item_sku”, columnList = “sku”, unique = true)
})
public class ShopItem extends PanacheEntity {
@Column(nullable = false, unique = true)
public String sku;
@Column(nullable = false)
public String title;
@Column(nullable = false)
public String artworkName;
@Column(nullable = false, precision = 12, scale = 2)
public BigDecimal price;
@Column(nullable = false)
public int stock;
@Column(length = 2000)
public String description;
}
Seed data on startup
We’ll just use a static import.sql for the initial data seed. Put it into src/main/resources
-- Seed data for Artwork table
INSERT INTO artwork (id, name, code) VALUES
(1, ‘Starry Night’, ‘ART-0001’),
(2, ‘Mona Lisa’, ‘ART-0002’),
(3, ‘The Persistence of Memory’, ‘ART-0003’),
(4, ‘Girl with a Pearl Earring’, ‘ART-0004’);
-- Seed data for ShopItem table
INSERT INTO shop_item (id, sku, title, artworkName, price, stock, description) VALUES
(1, ‘SKU-0001’, ‘Starry Night Print’, ‘Starry Night’, 29.99, 50, ‘Post-Impressionist masterpiece with swirling night sky.’),
(2, ‘SKU-0002’, ‘Mona Lisa Print’, ‘Mona Lisa’, 35.99, 30, ‘Portrait renowned for enigmatic expression.’),
(3, ‘SKU-0003’, ‘Persistence of Memory Print’, ‘The Persistence of Memory’, 32.99, 25, ‘Surreal landscape with melting clocks.’),
(4, ‘SKU-0004’, ‘Girl with Pearl Earring Print’, ‘Girl with a Pearl Earring’, 28.99, 40, ‘Tronie with luminous light and gaze.’);
REST endpoints
Let’s just quickly implement some endpoints for debugging and optional integration into a standalone Shop UI.
package com.ibm.txc.museum.shop.api;
import java.util.List;
import com.ibm.txc.museum.shop.domain.ShopItem;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.NotFoundException;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.PathParam;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
@Path(”/api”)
@Produces(MediaType.APPLICATION_JSON)
@Consumes(MediaType.APPLICATION_JSON)
public class ItemResource {
@GET
@Path(”/artworks/{name}/items”)
public List<ShopItem> byArtwork(@PathParam(”name”) String artworkName) {
return ShopItem.list(”artworkName = ?1 order by title”, artworkName);
}
@GET
@Path(”/items/{id}”)
public ShopItem byId(@PathParam(”id”) Long id) {
ShopItem i = ShopItem.findById(id);
if (i == null)
throw new NotFoundException();
return i;
}
}MCP: a proper tool for LLMs
Now expose a real MCP tool the right way. We’ll support both transports:
Streamable HTTP at
/mcp(newer protocol).HTTP/SSE at
/mcp/sse(deprecated but widely supported). (docs.quarkiverse.io)
Define a tool: getInventoryItemsByCode. The MCP server will generate JSON schema for inputs and outputs and a Dev UI to inspect. It also supports pagination and traffic logging. (docs.quarkiverse.io)
package com.ibm.txc.museum.shop.mcp;
import java.math.BigDecimal;
import com.ibm.txc.museum.shop.domain.Artwork;
import com.ibm.txc.museum.shop.domain.ShopItem;
import io.quarkiverse.mcp.server.TextContent;
import io.quarkiverse.mcp.server.Tool;
import io.quarkiverse.mcp.server.ToolArg;
import io.quarkiverse.mcp.server.ToolResponse;
import io.quarkus.logging.Log;
import jakarta.inject.Singleton;
@Singleton
public class MuseumShopMcpServer {
@Tool(name = “getInventoryItemsByCode”, description = “List inventory items for an artwork by its title”, structuredContent = true)
public ToolResponse getInventoryItemsByCode(
@ToolArg(description = “artwork names like ‘Girl with a Pearl Earring’”) String name) {
if (name == null || name.isBlank()) {
return ToolResponse.error(”Artwork name must be provided”);
}
Artwork artwork = Artwork.find(”name = ?1”, name).firstResult();
Log.info(artwork);
ShopItem shopItem = ShopItem.find(”id = ?1”, artwork.id).firstResult();
Log.info(shopItem);
if (shopItem == null) {
return ToolResponse.error(”No shop item found for artwork name: “ + name);
}
AvailableItems availableItems = new AvailableItems(
shopItem.sku,
shopItem.title,
shopItem.artworkName,
shopItem.price,
shopItem.stock,
shopItem.description);
return ToolResponse.success(new TextContent(availableItems.toString()));
}
public record AvailableItems(String sku, String title, String artworkName, BigDecimal price, int stock,
String description) {
}
}
Why structuredContent=true? Since mid-2025, MCP allows structured tool results. Some clients still expect a text mirror, so keep compatibility enabled if you integrate with older SDKs. (docs.quarkiverse.io)
Integrate with the existing Museum App
Go back to the museum-app and add the new mcp server to the application.properties
src/main/resources/application.properties
uarkus.langchain4j.mcp.museumshop.transport-type=streamable-http
quarkus.langchain4j.mcp.museumshop.url=http://localhost:8082/mcp
quarkus.langchain4j.mcp.museumshop.log-requests=true
quarkus.langchain4j.mcp.museumshop.log-responses=trueAnd now we need to add the new MCP tool to the ArtInspectorAi:
package com.ibm.txc.museum.ai;
import dev.langchain4j.data.image.Image;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import io.quarkiverse.langchain4j.RegisterAiService;
import io.quarkiverse.langchain4j.mcp.runtime.McpToolBox;
@RegisterAiService
public interface ArtInspectorAi {
@SystemMessage(”“”
Identify artwork from a visitor photo.
Return JSON with: title, artist, confidence, why, lates news, today, featured inventory item.
“”“)
@UserMessage(”“”
Photo: {{image}}
Use MCP tool getTimeContext to put into a time context.
Use MCP tool getArtNews Latest updates about the artwork.
Use MCP tool getInventoryItemsByCode To find the artwork in the museum shop.
“”“)
@McpToolBox({ “museum”, “museumshop” })
String identify(Image image);
}Update the HTML page
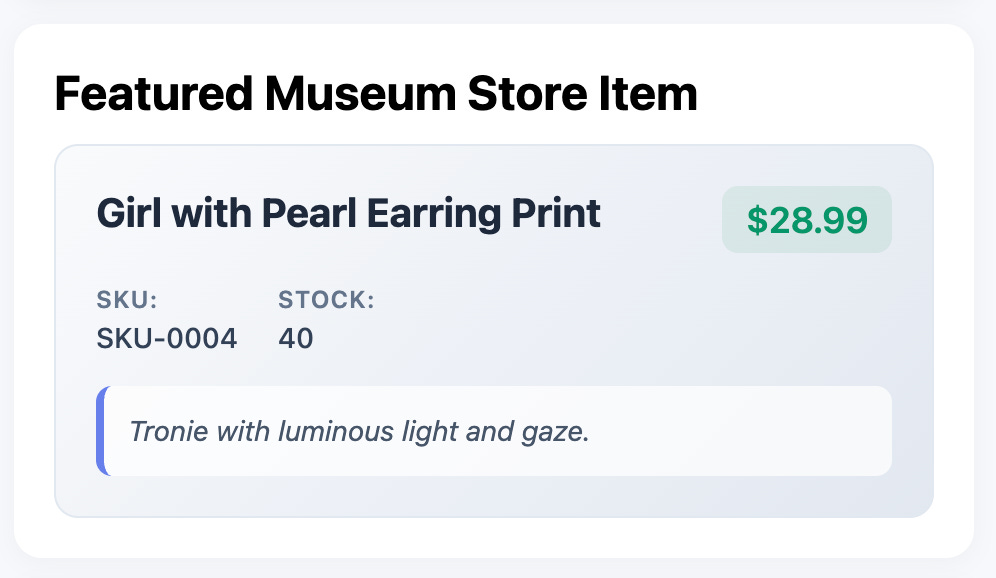
Let’s render the newly added information appropriately in the index.html template of the museum-app:
<!-- existing content prior to lines 48 -->
<!-- Featured Inventory Item -->
<div id=”featuredItemCard” class=”card” style=”display: none;”>
<h2 style=”margin:0 0 6px 0;”>Featured Museum Store Item</h2>
<div class=”featured-item”>
<div class=”featured-item-header”>
<h3 id=”featuredItemTitle” class=”featured-item-title”></h3>
<div id=”featuredItemPrice” class=”featured-item-price”></div>
</div>
<div class=”featured-item-details”>
<div class=”featured-item-detail”>
<span class=”featured-item-label”>SKU:</span>
<span id=”featuredItemSku” class=”featured-item-value”></span>
</div>
<div class=”featured-item-detail”>
<span class=”featured-item-label”>Stock:</span>
<span id=”featuredItemStock” class=”featured-item-value”></span>
</div>
</div>
<div class=”featured-item-description”>
<p id=”featuredItemDescription”></p>
</div>
</div>
</div>
<!-- existing content -->Also make sure to add the JavaScript section:
<!-- add after line 170 -->
// Populate featured inventory item if available
const featuredItemCard = document.getElementById(’featuredItemCard’);
if (result.featured_inventory_item) {
const item = result.featured_inventory_item;
document.getElementById(’featuredItemTitle’).textContent = item.title || ‘Unknown Item’;
document.getElementById(’featuredItemPrice’).textContent = ‘$’ + (item.price || ‘0.00’);
document.getElementById(’featuredItemSku’).textContent = item.sku || ‘N/A’;
document.getElementById(’featuredItemStock’).textContent = item.stock || ‘N/A’;
document.getElementById(’featuredItemDescription’).textContent = item.description || ‘No description available’;
featuredItemCard.style.display = ‘block’;
} else {
featuredItemCard.style.display = ‘none’;
}
Run and verify
Dev mode:
quarkus devTry:
GET http://localhost:8082/api/artworks/Mona%20Lisa/itemsPUT http://localhost:8082/api/items/1/stock/-1
MCP inspection:
Streamable HTTP endpoint:
http://localhost:8082/mcpLegacy SSE endpoint:
http://localhost:8082/mcp/sse
You can explore tools in Quarkus Dev UI and with the MCP Inspector.
Two Styles of MCP Tool Implementation
If you have read the initial version of this blog post, you will recognize that I am using a different implementation approach for the original MuseumMcp Server and the new one today.
When exposing business logic as MCP tools, Quarkus gives you two main implementation patterns. At first glance they look similar, but they differ in schema quality and control.
Structured ToolResponse with @ToolArg
@Tool(
name = “getInventoryItemsByCode”,
description = “List inventory items for an artwork by its title”,
structuredContent = true
)
public ToolResponse getInventoryItemsByCode(
@ToolArg(description = “artwork codes like ‘Girl with a Pearl Earring’”) String name) {
...
}This style uses the ToolResponse type and @ToolArg annotations. It is the modern, recommended approach:
ToolResponselets you signal success or error, add metadata, and enforce structured outputs.@ToolArgenriches the input schema with descriptions, which makes the tool easier for LLMs to select correctly.structuredContent=trueensures downstream consumers get predictable JSON instead of free-form text.
Use this whenever you want reliable schemas, validated inputs, and clarity in production environments.
Plain object return without annotations
@Tool(
name = “getArtNews”,
description = “Fetch latest updates from Wikipedia”
)
public News getArtNews(String title) {
...
}This is the shortcut style:
The server will auto-serialize the returned POJO (
News) into JSON.Arguments are bare, with no additional descriptions. The schema is weaker and easier for models to misuse.
No
ToolResponsemeans you cannot mark errors or control how content is mirrored.
It’s fine for prototypes or very simple cases, but it lacks the robustness you want for tools that live in production.
Rule of Thumb
Prefer the structured ToolResponse form with explicit @ToolArg descriptions. Schema clarity trumps convenience. LLMs select tools based on the quality of the schema, and debugging is much easier when you can return ToolResponse.error(...) instead of hoping a generic POJO is enough.
Production notes
Use Streamable HTTP, not legacy SSE, going forward. SSE is still supported but marked deprecated in MCP docs. New work should prefer
/mcp.Schema everything. Add Bean Validation annotations to your tool inputs so the MCP server produces rich JSON Schemas for clients.
Pagination by default. If your tool can return many items, enable MCP server pagination for tools/resources.
Keep tools narrow. Tool naming and narrow scope improves selection accuracy. Large tool menus degrade model performance; consider routing or retrieval to shortlist tools.
Traffic logging. Turn it on in staging. Limit message size.
Dev Services PostgreSQL. Great for local; switch to managed PostgreSQL with credentials and SSL in production. Quarkus guide covers Panache and JDBC Postgres usage. (Quarkus)
Lessons learned: MCP best practices
Transport choice matters. Prefer Streamable HTTP for browser or gateway scenarios. Keep stdio only for CLI-spawned agents and local tools. HTTP/SSE remains for compatibility during the transition window.
Tools should be few, focused, and well described. In practice, most models handle a small to moderate set reliably. Selection quality drops as the list grows. Use routing, tags, or a retrieval step to trim candidates.
Structured outputs help. Use
structuredContentso downstream code and evaluators can assert on fields, not text blobs. Some clients still want mirrored text; keep compatibility on where needed.Time bounds and cancellations. Set default timeouts; check for cancellation to avoid dangling work. The Quarkiverse MCP server exposes both features directly.
Observability first. Enable traffic logging with limits. Add request IDs in logs. Keep PII out of logs by default.
SSE vs WebSockets. SSE is simple, works through proxies, and is perfect for one-way inventory streams. For bidirectional sessions, prefer Streamable HTTP or WebSocket transports.
What-ifs and variations
Reactive vs imperative. Everything here is imperative. Switching to reactive repositories and Mutiny is straightforward if you need higher concurrency.
AuthZ. Add OIDC bearer auth on
/apiand/mcp. In cross-service calls, forward tokens automatically with Quarkus OIDC client filters.
MCP Tools vs. Messaging for Microservice Interactions
The Model Context Protocol (MCP) introduces a new way for applications to talk to each other. Instead of exchanging messages on a queue or topic, you expose tools: discrete, typed functions that an LLM or another client can call. At first glance this feels like RPC. The difference is that the consumer is not another microservice written by a human, but a model selecting and chaining tools based on schema descriptions.
Microservice Interactions with MCP
Tools are discoverable: the server advertises its capabilities in a machine-readable schema.
Calls are synchronous by default. An LLM can ask for “list inventory by artwork” and immediately get a JSON payload.
Structured input/output matters more than ever, because the caller is a model reasoning about your API, not a developer reading docs.
Tooling fits scenarios where you want tight coupling to a reasoning loop. For example: a customer support agent that checks billing data via an MCP tool before drafting a reply.
Messaging with Kafka or RabbitMQ
Messaging decouples producers and consumers. Services exchange events or tasks without knowing who will consume them.
Calls are asynchronous. Latency, retries, and backpressure are part of the design.
It’s a natural fit for event-driven domains: fraud detection, order fulfillment, telemetry processing.
Developers, not LLMs, design the topics and payloads, and schema registries ensure type safety across services.
Where MCP Tools Fit, Where Messaging Wins
MCP tools are attractive when the interaction is direct, request/response, and reasoning-driven. A model acting as a “brain” can call a set of tools just like it would call functions in code. The design emphasis is on schema clarity, not throughput.
Messaging is still superior when you need scalable, decoupled, high-throughput pipelines. LLMs don’t select tools well when there are hundreds of them; similarly, they are not well suited to manage long-lived event streams.
Architectural Rule of Thumb
If you need an LLM to orchestrate across services, expose tools.
If you need services to coordinate at scale, emit events.
In practice, the two will coexist: MCP for reasoning gateways, messaging for event backbones.
The museum gift shop app shows how far Quarkus has come as a platform for building AI-ready microservices. With just a few extensions you created REST endpoints and a streaming SSE feed, and a fully compliant MCP server that an LLM can use as a tool. Along the way, you saw the difference between quick POJO-based tools and robust ToolResponse-based implementations, and why schema clarity matters when models select actions.
The lesson is that MCP tools are not a replacement for messaging systems like Kafka. They solve a different problem: enabling reasoning engines to invoke well-defined functions across services. Messaging still powers decoupled, high-throughput pipelines. The future enterprise stack will use both: MCP for reasoning gateways and LLM-driven flows, messaging for scale and reliability.
Quarkus makes it easy to experiment with both worlds in the same project. That balance between AI-friendly protocols on one side, production-grade microservice patterns on the other is what gives Java developers an edge in the era of AI-infused applications.
Ship it.